


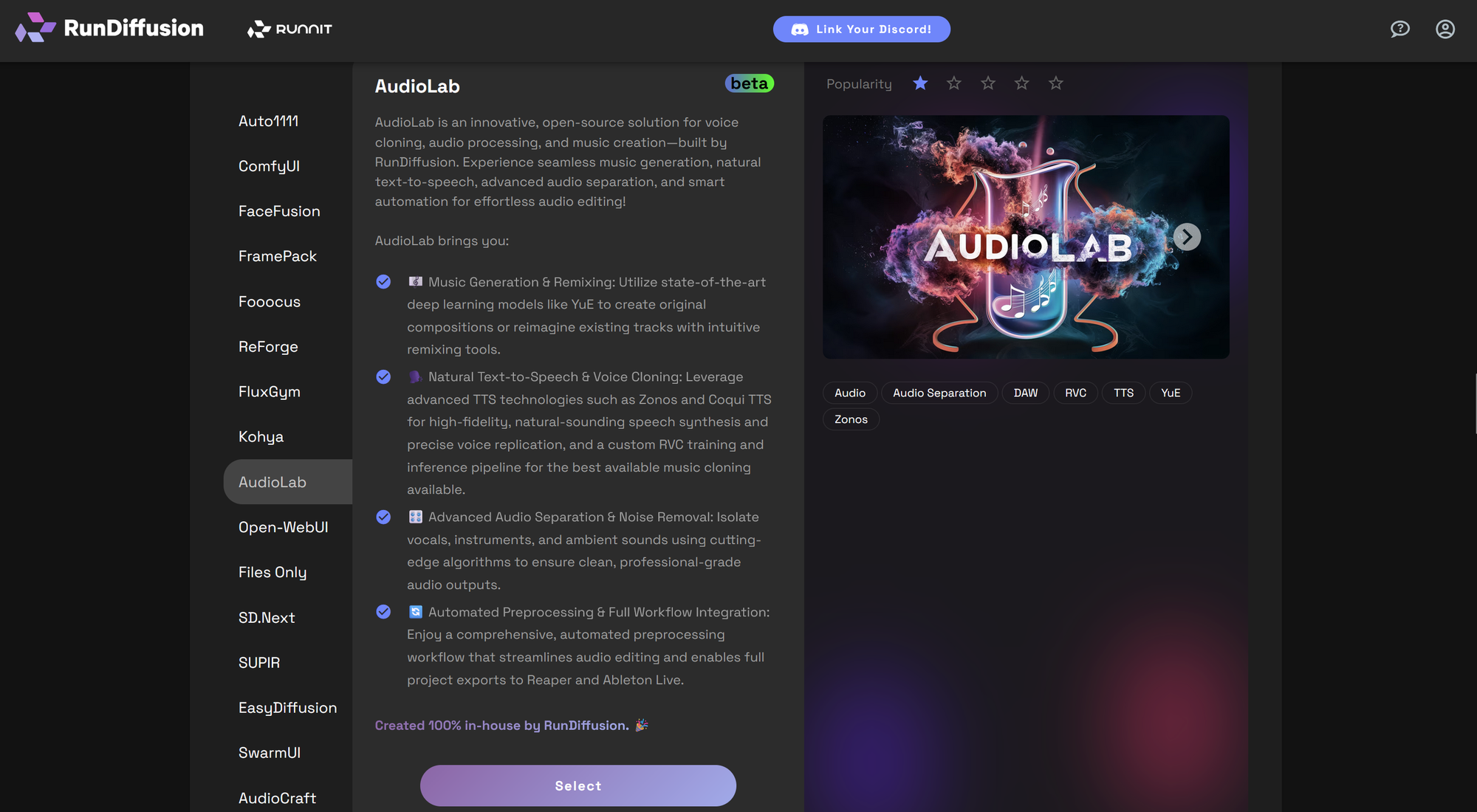
Audiolab on RunDiffusion has grown into a complete cloud-based AI audio suite, supporting voice cloning, music generation, transcription, timbre transfer, and more. Whether you're making original voices, transforming instrument tones, or generating ambient audio from prompts, Audiolab now delivers a seamless experience.
Here’s your updated deep dive into all available tools and features as of 2025.
Quick Summary of What's Inside
| Tab | Purpose |
|---|---|
| Process | Use preloaded and trained voice models instantly |
| Train RVC | Train your own voice model from recordings |
| Music | Generate music/audio using multiple AI engines |
| TTS | Convert text to speech with dozens of models |
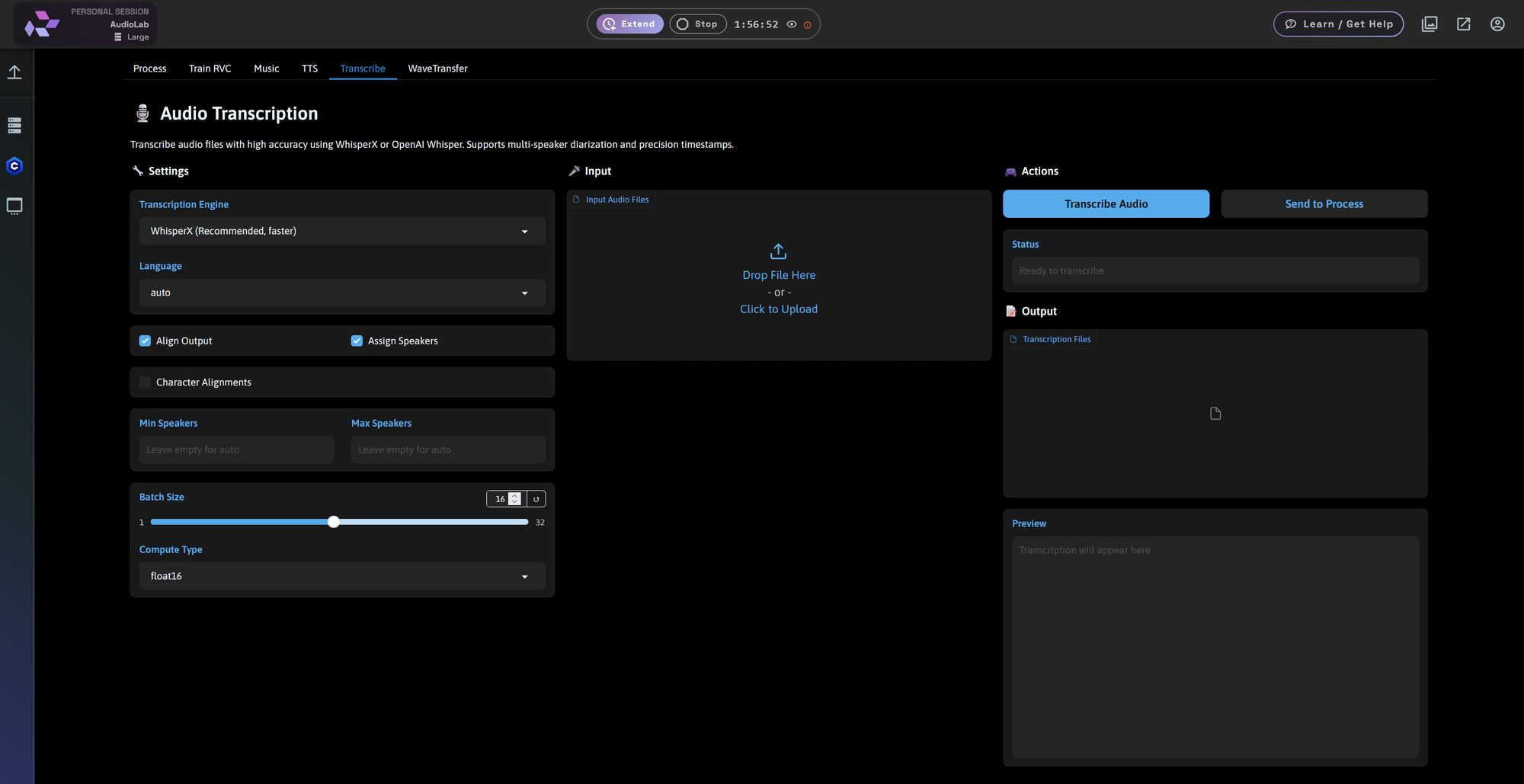
| Transcribe | Turn speech/audio into text |
| WaveTransfer | Perform instrument timbre transfer |
Process: We’ve Added Voices!
One of the most requested features is finally here: preloaded voice models.
No need to train a model to get started — just select a persona and generate. These character-driven voices let you experiment with different tones, styles, and moods.
Included voice personas:
- Crimson Legacy – Deep and poetic with assertive presence
- Electric Indigo – Raw, emotional, and charged with energy
- Smoky Spirit – Gritty, with a raspy vintage edge
- Sunset Amber – Warm, mellow, and laid-back
- Mystic Onyx – Unpredictable and eclectic
- Velvet Violet – Rich, soulful, and full of nuance
These are great for voice testing, prototyping, or creative music with AI vocals.
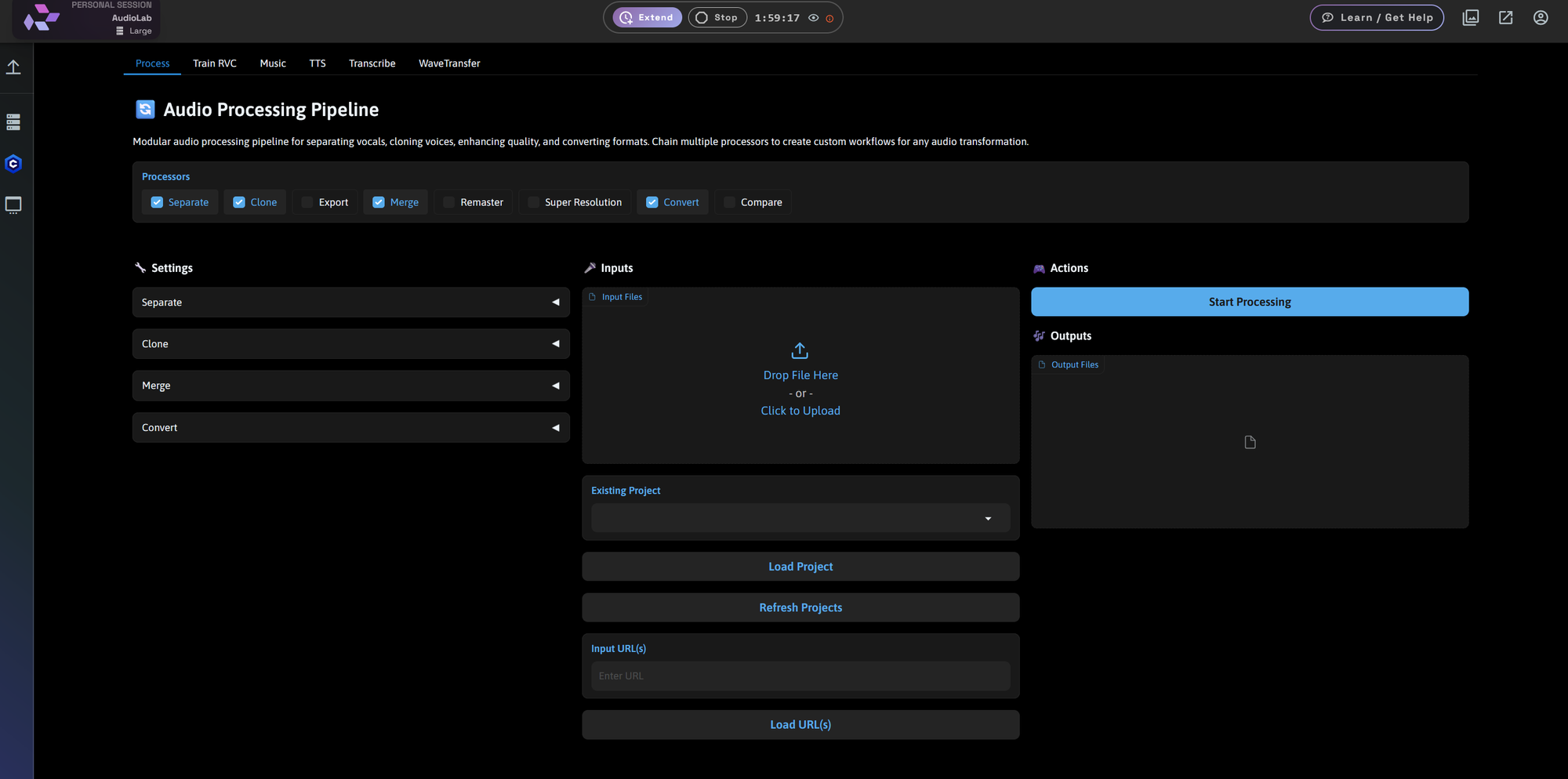
Train RVC: Build Your Own Voice Model
In the Train RVC tab, you can upload your own voice dataset and train a custom voice conversion model.
Key features:
- Upload ~30–60 minutes of audio or input audio URLs
- Optional vocal separation
- Adjustable training epochs (2–4000) and batch size (1–40)
- Index building for smoother inference
This tool is perfect for content creators, musicians, or voice actors wanting a personal voice model in the cloud.
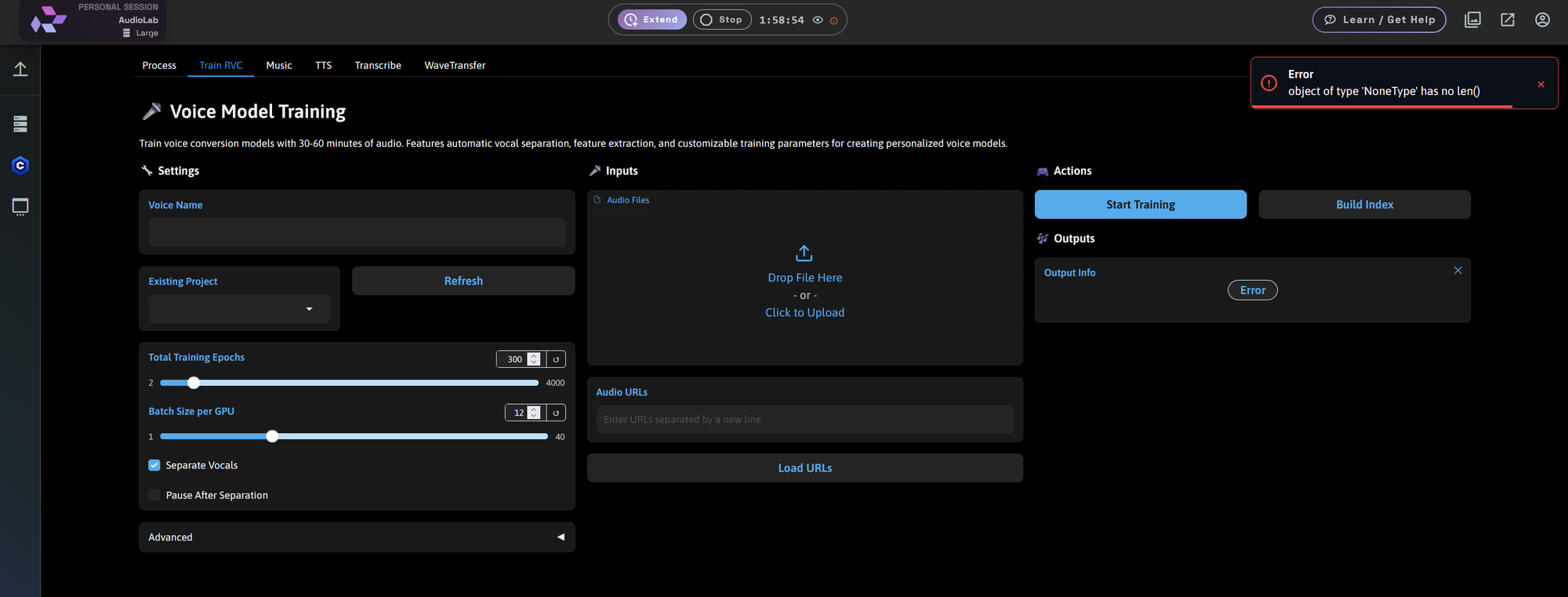
Music: Text-to-Audio with Multiple Engines
The Music tab now includes several model backends for generating music and sound from text prompts.
Stable Audio
- Generate ambient textures, instrumentals, or sound effects
- Controls: duration, inference steps, seed, variation count
- Negative prompting support
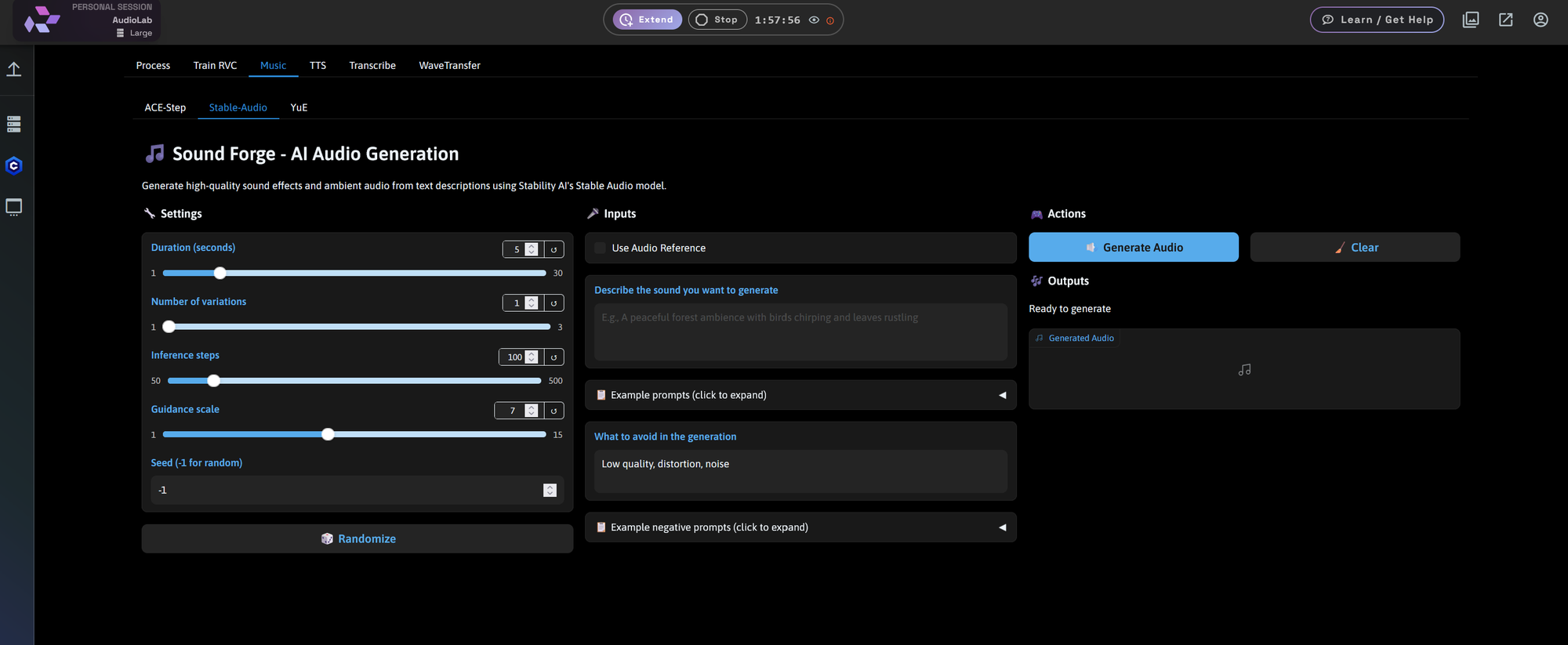
ACE-Step
- Generate structured music and songs up to 4 minutes long
- Supports lyrics input and LoRA models (e.g., RapMachine)
- Base model: ACE-Step-v1-3.5B
- Controls: duration, seed, advanced generation parameters
YuE
- Create full tracks with vocals and instrumentation
- Input genre tags, structured lyrics ([verse], [chorus])
- Supports optional reference audio
Use these to score video content, generate creative soundscapes, or experiment with generative music ideas.
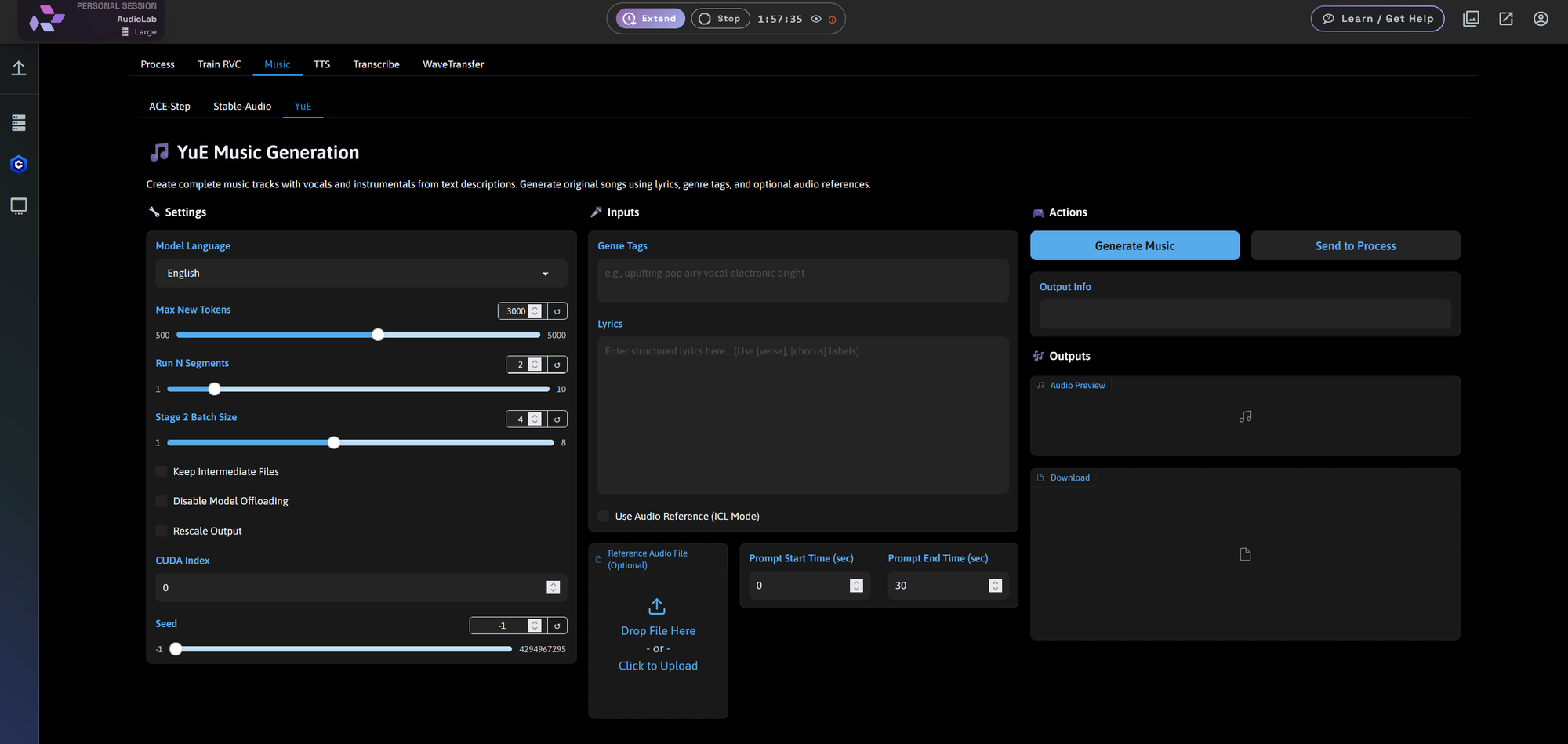
TTS (Text-to-Speech): Huge Model Library
The TTS tab includes a wide range of voice synthesis models and customization options:
Model highlights include:
- DIA – Clean dialog synthesis
- Zonos – Emotionally rich voice with optional style tags
- Tacotron2, Glow-TTS, Speedy-Speech, VITS, FastPitch, etc.
Features:
- Voice cloning from reference audio
- Speaker tagging for multi-speaker text (e.g., [S1], [S2])
- Language selection and speed control
Great for podcasting, video narration, dialogue generation, or storytelling.
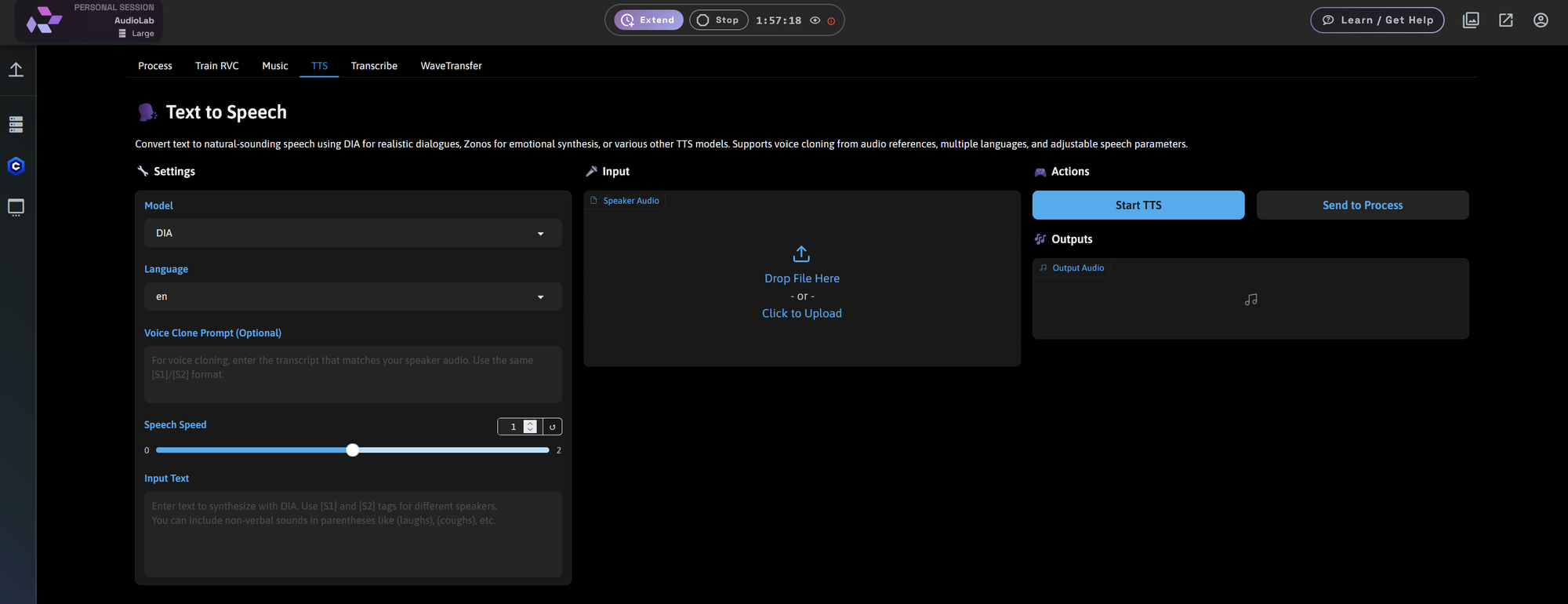
Transcribe: WhisperX + Whisper in the Cloud
Upload an audio file and get clean, speaker-separated transcriptions in just minutes.
Powered by:
- WhisperX (recommended)
- OpenAI Whisper
Features:
- Speaker diarization (multi-speaker labeling)
- Timestamps with word alignment
- Batch size and compute control
Ideal for interviews, meetings, subtitle generation, or audio cleanup.
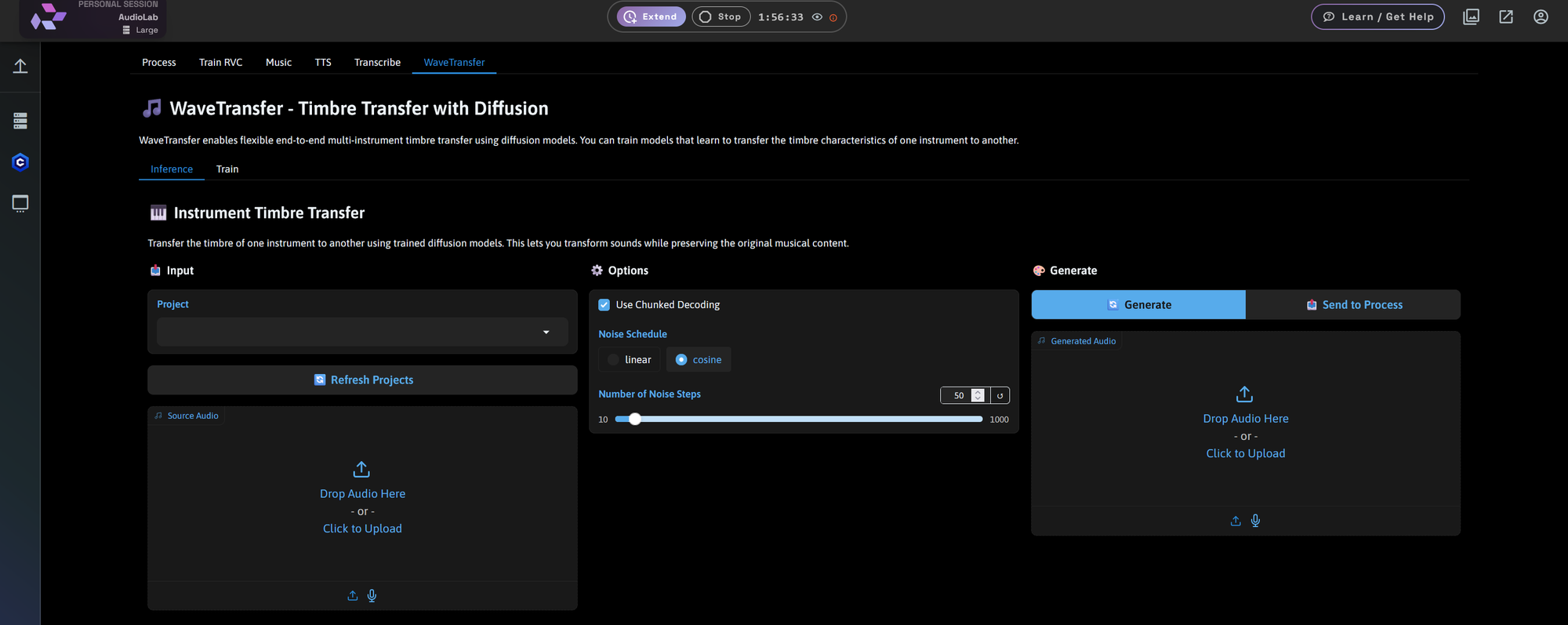
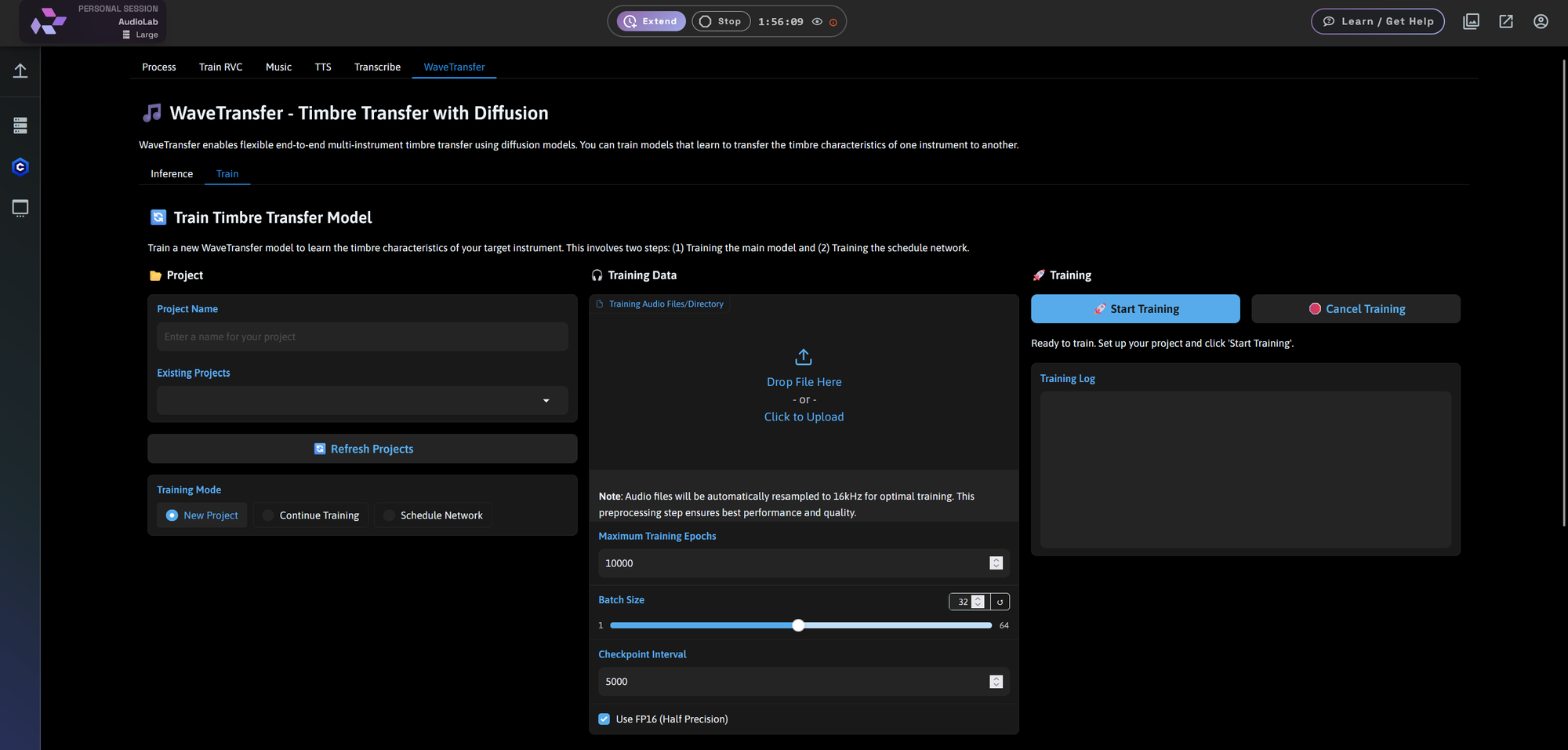
WaveTransfer: Timbre Transfer with Diffusion
This feature allows you to transfer the timbre of one instrument to another while preserving the original musical structure.
Two fully supported modes:
Inference
- Apply a trained timbre model to new audio
- Select project
- Control noise steps (10–1000)
- Use chunked decoding for smoother generation
Train
- Train a new model to learn the timbre of your chosen instrument
- Input training data and project details
- Two-phase training: model and schedule network
- Start, cancel, and monitor training sessions
Perfect for composers, remix artists, and sound designers exploring new tonal blends.
How to Get Started
Log in to RunDiffusion
Go to Open Source Apps
Select Audiolab from the left panel then click Select.
On the setup screen change server size to Large then click Launch to start your session.
Begin using any of the 6 discussed in this article.
Why Use Audiolab on RunDiffusion?
- Hosted on high-performance GPUs
- Built for creators: no coding required
- Offers both fast prototyping and deep customization
- Save time with preloaded voices and one-click workflows
Whether you’re a content creator, voice artist, developer, or musician, Audiolab offers a modular toolset to accelerate your audio projects.
Previous article: Audiolab - A Quick Overview


