


Introduction to Flux LoRA Training with Kohya
Flux LoRA Training is a wonderful technique for tuning large models using Low-Rank Adaptation (LoRA). By reducing the number of trainable parameters, this method streamlines the fine-tuning process, saving both time and computational resources. It’s an excellent approach for customizing models to generate specific styles, images, or concepts, without the need to retrain the entire model from scratch.
In this tutorial, we’ll walk you through the steps of setting up Flux LoRA training in Kohya. Using the flux_training.json file, which includes pre-configured parameters, you'll be able to simplify the training process and focus on what matters most—getting the results you want.
Step-by-Step Guide to Flux LoRA Training
1. Download the flux_training.json File
First, you’ll need the flux_training.json file that contains all the preset configurations for your LoRA training. You can download it here. Save it in an easily accessible folder on your system because you’ll upload it to the server shortly.
2. Launch Kohya
Next, launch Kohya.
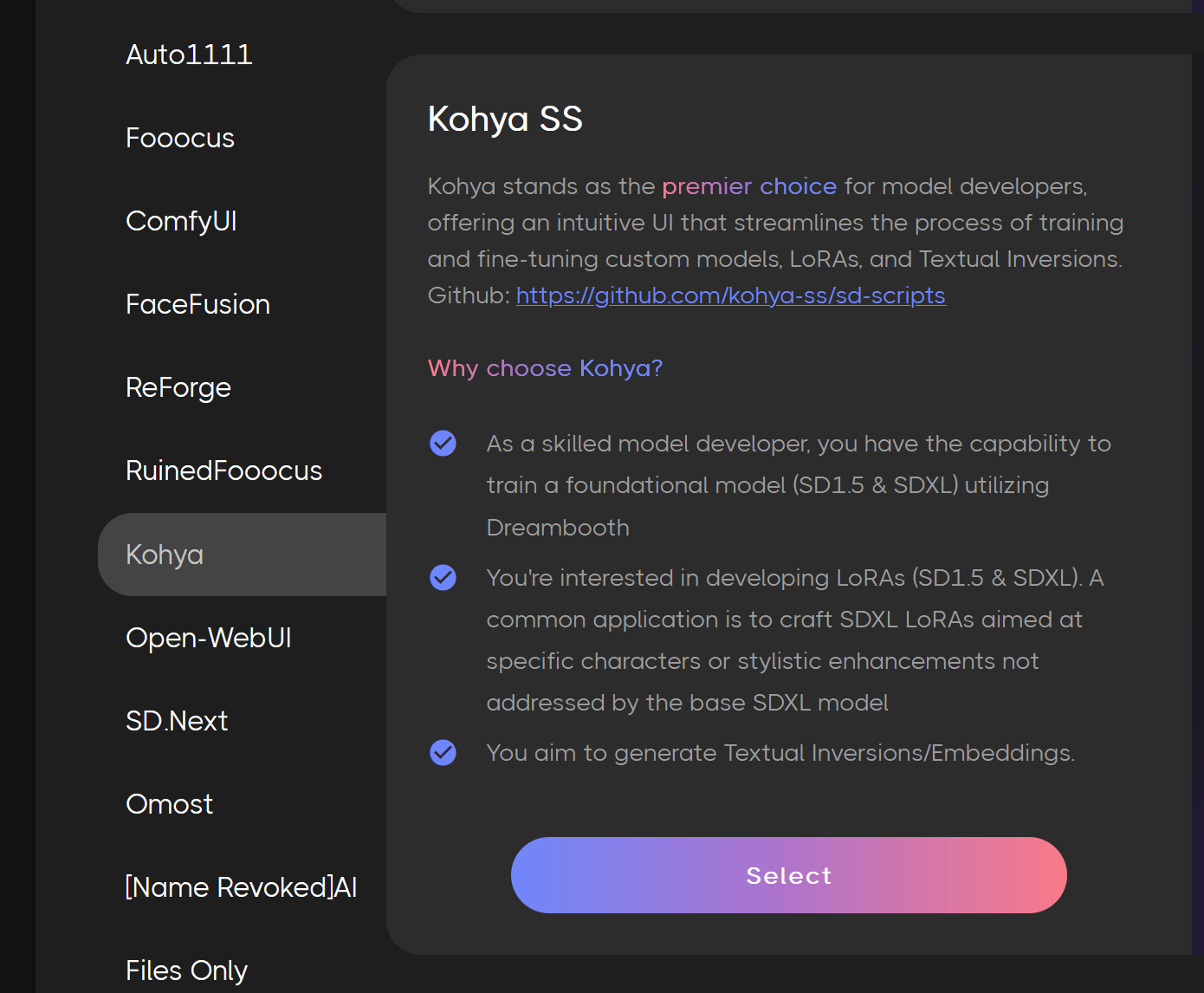
Once Kohya is running:
Navigate to the LoRA tab at the top of the interface. This is where you'll input all the necessary parameters for your training session.
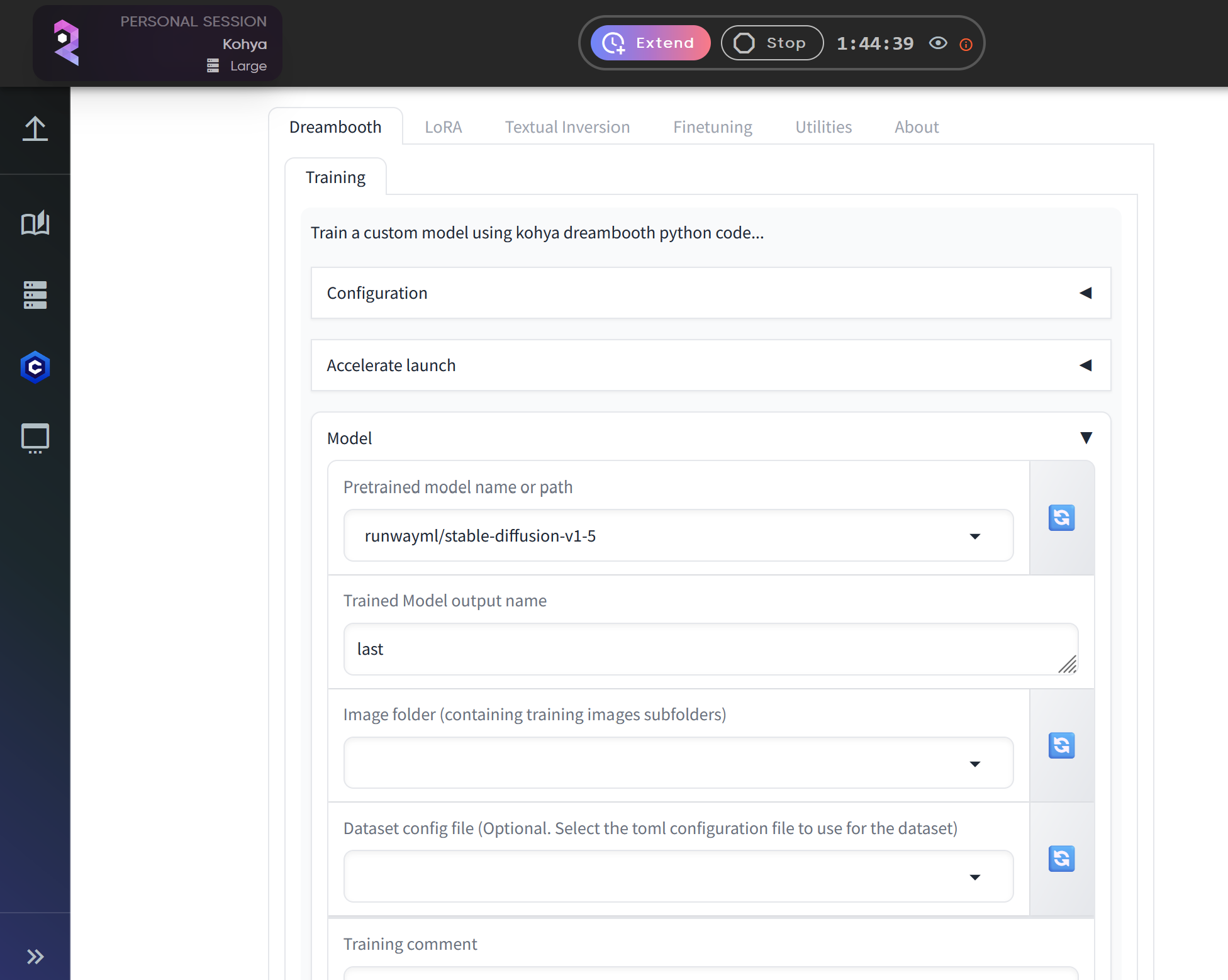
This is the Lora training tab. We'll fill out all the information here in a second but let's first upload our dataset.
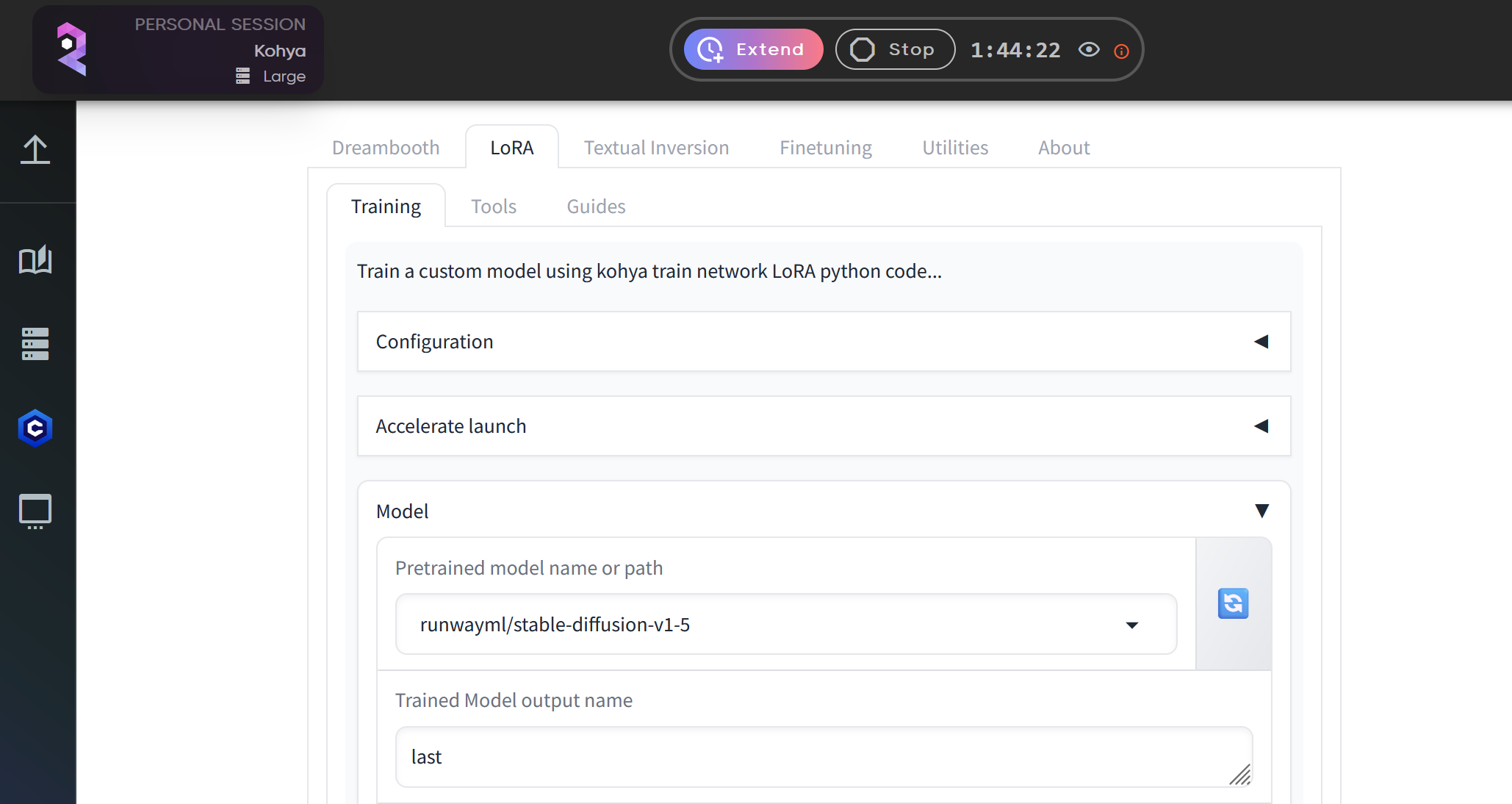
3. Upload Your Dataset
Before configuring the LoRA settings, we need to upload the dataset.
In the LoRA tab, click the square icon with an upward arrow (located at the top right). This opens the file manager in a new browser window.
On the left side, create a new folder and name it train.
Inside the train folder, create another folder called flux, and within that, create a folder for your dataset. For this example, we are creating a folder named minfluencer for a dataset of male influencer images.
Upload your dataset (images and corresponding text files) to the folder you created. For this example I would upload them to /train/minfluencer/ remember your images should be 512x512 or 1024x1024.
4. Upload and Configure the flux_training.json File
Now, return to the LoRA tab in Kohya.
Click on the Configuration section.
In the configuration field, type:/mnt/private/train/flux_training.json and click the Enter symbol on the right of the save symbol.
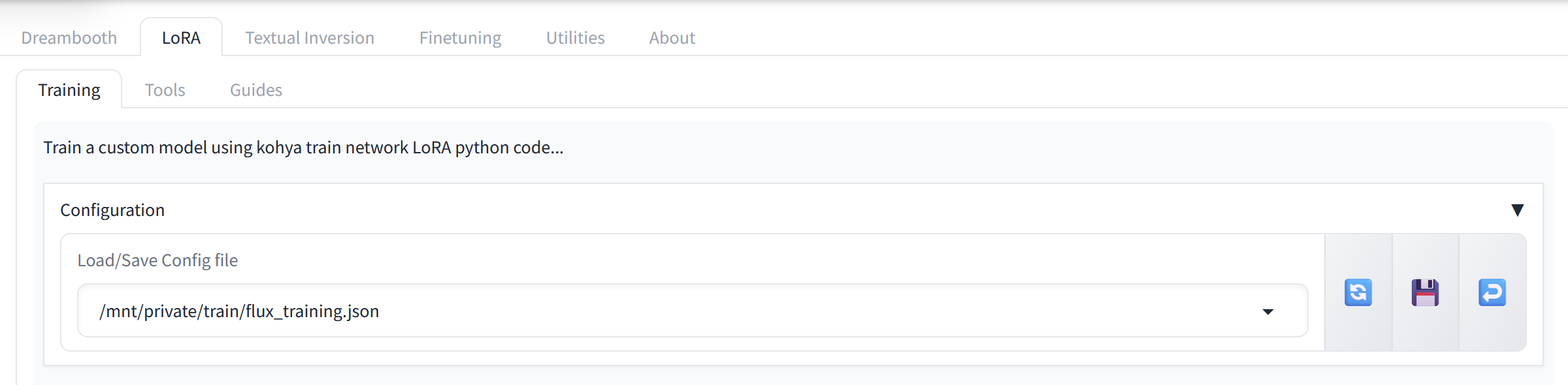
This will automatically load all the preset parameters contained in the JSON file.
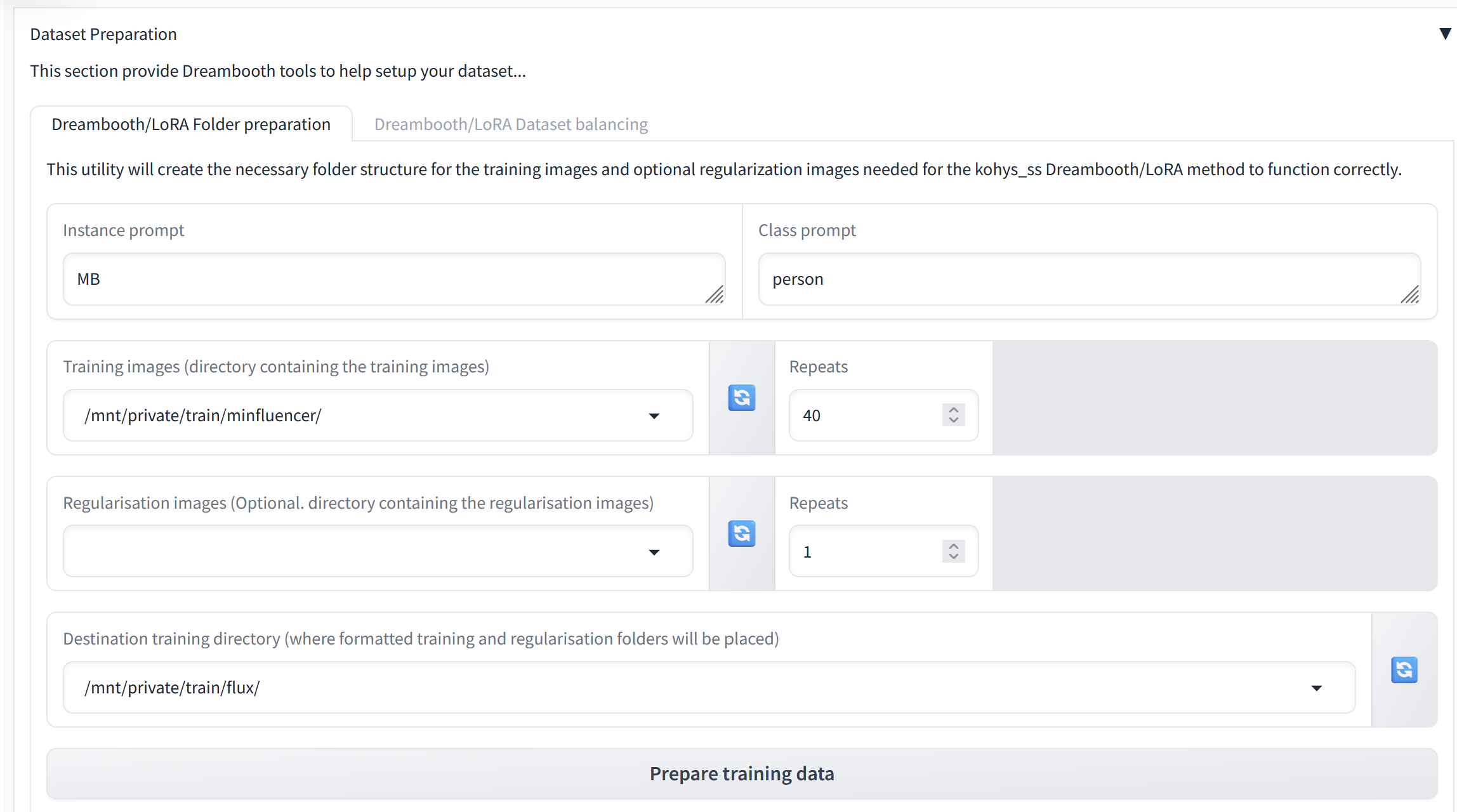
5. Preparing the Dataset
Before starting the training process, ensure your dataset is properly prepared:
- If you used a trigger word in your dataset (such as a specific style, object, or persona), enter it in the Instance Prompt field.
- Even if no trigger word is used, an instance prompt is required for the training to begin. Common prompts include terms like "person", "style", or "animal."
- Set the Training Image Directory to:
/mnt/private/train/folder_with_your_dataset - Set the Destination Training Directory to:
/mnt/private/train/flux/ - For best results on a Large server, we recommend an image resolution of 512x512 when training with Flux, as it is very VRAM-intensive.
After entering these values, click Prepare Training Data.
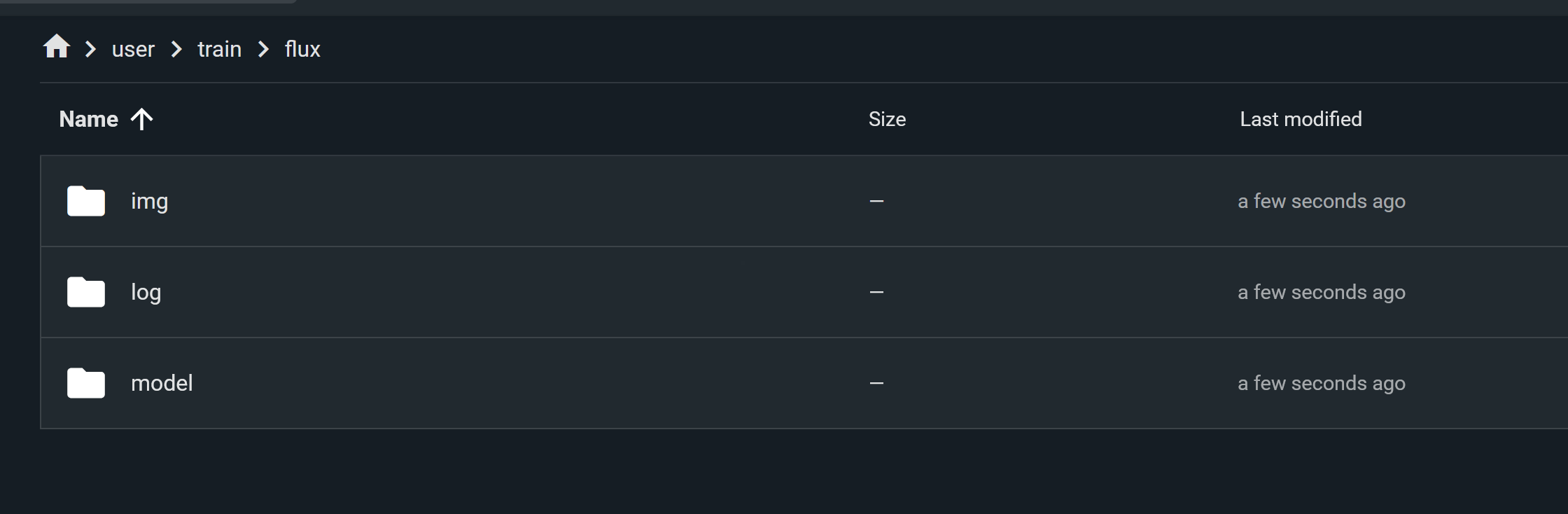
6. Starting the Training Process
Once the dataset is prepared, navigate to the train/flux folder in your file manager. You should see three new folders created. If these folders are missing, recheck your paths from the previous step.
Scroll down in Kohya’s interface and click Start Training .

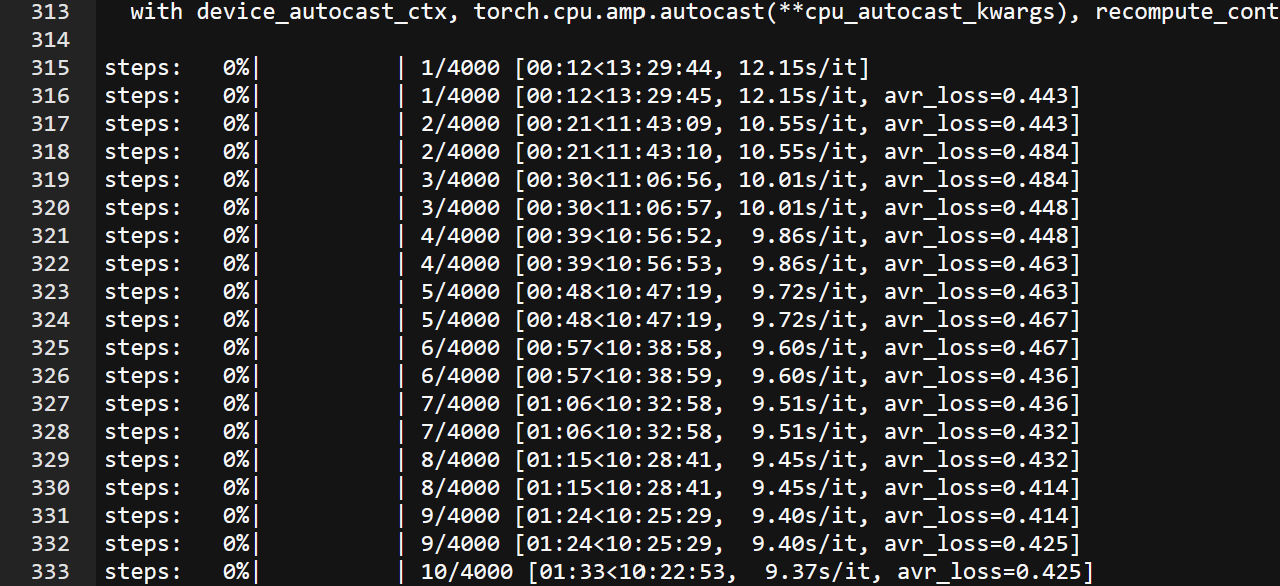
7. Monitoring the Training Process
Kohya can sometimes be finicky when displaying logs. To monitor the most accurate log, navigate to the /logs/ folder. Open the KOYA.log file to check the current status of your training session. You can refresh this file periodically to track your progress.

Flux LoRA training is generally much faster compared to training models like SDXL. You should expect good results between 1,000 to 2,000 steps, especially when fine-tuning for specific personas or styles (like our male influencer dataset).
Testing Your Trained Model
Once the training process is complete, it’s time to test the LoRA you created. Use the custom lora in your preferred generative application that supports flux, and evaluate how well it performs with the intended style or subject (in this case, the male influencer). You will need to place the safetensor file located in the /train/flux/models folder and put it inside /models/lora/custom/flux.




Final Thoughts
Flux LoRA training in Kohya is a powerful way to fine-tune flux models for highly specific results. By following this step-by-step guide and using the pre-configured flux_training.json file, you can significantly reduce the time and resources required to train your models, while still achieving high-quality, personalized outputs.
For more insights into working with AI generative tools, check out our Rundiffusion docs or explore the basics of LoRa Training with Kohya.
Full List of Parameters in flux_training.json
- LoRA Type: Flux1
- LyCORIS Preset: full
- Adaptive Noise Scale: 0
- Additional Parameters: (empty)
- AE:
/mnt/shared-assets-lg/vae/ae.sft - Apply T5 Attention Mask: true
- Async Upload: false
- Block Alphas: (empty)
- Block Dims: (empty)
- Block LR Zero Threshold: (empty)
- Bucket No Upscale: true
- Bucket Resolution Steps: 64
- Bypass Mode: false
- Cache Latents: true
- Cache Latents to Disk: true
- Caption Dropout Every N Epochs: 0
- Caption Dropout Rate: 0
- Caption Extension:
.txt - CLIP_L:
/mnt/shared-assets-lg/CLIP/clip_l.safetensors - CLIP Skip: 1
- Color Augmentation: false
- Constrain: 0
- Conv Alpha: 1
- Conv Block Alphas: (empty)
- Conv Block Dims: (empty)
- Conv Dim: 1
- CPU Offload Checkpointing: false
- Dataset Config: (empty)
- Debiased Estimation Loss: false
- Decompose Both: false
- Dim from Weights: false
- Discrete Flow Shift: 3
- Dora WD: false
- Down LR Weight: (empty)
- Dynamo Backend: no
- Dynamo Mode: default
- Dynamo Use Dynamic: false
- Dynamo Use Fullgraph: false
- Enable All Linear: false
- Enable Bucket: true
- Epoch: 1
- Extra Accelerate Launch Args: (empty)
- Factor: -1
- Flip Augmentation: false
- Flux1 Cache Text Encoder Outputs: true
- Flux1 Cache Text Encoder Outputs to Disk: true
- Flux1 Checkbox: true
- FP8 Base: true
- FP8 Base UNET: false
- Full BF16: true
- Full FP16: false
- GPU IDs: (empty)
- Gradient Accumulation Steps: 1
- Gradient Checkpointing: true
- Guidance Scale: 1
- High VRAM: false
- Huber C: 0.1
- Huber Schedule: snr
- Huggingface Path in Repo: (empty)
- Huggingface Repo ID: (empty)
- Huggingface Repo Type: (empty)
- Huggingface Repo Visibility: (empty)
- Huggingface Token: (empty)
- Image Attention Dimension: (empty)
- Image MLP Dimension: (empty)
- Image Module Dimension: (empty)
- Input Dimensions: (empty)
- IP Noise Gamma: 0
- IP Noise Gamma Random Strength: false
- Keep Tokens: 0
- Learning Rate: 0.0003
- Log Config: false
- Log Tracker Config: (empty)
- Log Tracker Name: (empty)
- Log With: (empty)
- Logging Directory:
/mnt/private/train/flux/log/ - LoRA+ LR Ratio: 0
- LoRA+ Text Encoder LR Ratio: 0
- LoRA+ UNET LR Ratio: 0
- Loss Type: l2
- Low VRAM: false
- LR Scheduler: constant
- LR Scheduler Args: (empty)
- LR Scheduler Num Cycles: 1
- LR Scheduler Power: 1
- LR Scheduler Type: (empty)
- LR Warmup: 0
- LR Warmup Steps: 0
- Main Process Port: 0
- Masked Loss: false
- Max Bucket Resolution: 2048
- Max Data Loader Workers: 0
- Max Gradient Norm: 1
- Max Resolution: 1024x1024
- Max Time Step: 1000
- Max Token Length: 75
- Max Train Epochs: 0
- Max Train Steps: 4000
- Mem Eff Attention: false
- Mem Eff Save: false
- Metadata Author: (empty)
- Metadata Description: (empty)
- Metadata License: (empty)
- Metadata Tags: (empty)
- Metadata Title: (empty)
- Mid LR Weight: (empty)
- Min Bucket Resolution: 256
- Min SNR Gamma: 7
- Min Time Step: 0
- Mixed Precision: bf16
- Model List: custom
- Model Prediction Type: raw
- Module Dropout: 0
- Multi GPU: false
- Multi-Resolution Noise Discount: 0.3
- Multi-Resolution Noise Iterations: 0
- Network Alpha: 16
- Network Dimension: 16
- Network Dropout: 0
- Network Weights: (empty)
- Noise Offset: 0.05
- Noise Offset Random Strength: false
- Noise Offset Type: Original
- Number of CPU Threads per Process: 2
- Number of Machines: 1
- Number of Processes: 1
- Optimizer: AdamW8bit
- Optimizer Args: (empty)
- Output Directory:
/mnt/private/train/flux/model/ - Output Name: Flux_Model_name
- Persistent Data Loader Workers: false
- Pretrained Model Name or Path:
/mnt/models/flux/flux1-dev.safetensors - Prior Loss Weight: 1
- Random Crop: false
- Rank Dropout: 0
- Rank Dropout Scale: false
- Regularization Data Directory: (empty)
- Rescaled: false
- Resume: (empty)
- Resume from Huggingface: (empty)
- Sample Every N Epochs: 0
- Sample Every N Steps: 200
- Sample Prompts: "abstract college thesis project, portraiture, thread, clay, sand, dirt, colorful, vibrant, abstraction, crystal --w 832 --h 1216 --s 20 --l 4 --d 42"
- Sample Sampler: euler
- Save as Bool: false
- Save Every N Epochs: 1
- Save Every N Steps: 200
- Save Last N Steps: 0
- Save Last N Steps State: 0
- Save Model As: safetensors
- Save Precision: bf16
- Save State: false
- Save State on Train End: false
- Save State to Huggingface: false
- Scale V Pred Loss Like Noise Pred: false
- Scale Weight Norms: 0
- SDXL: false
- SDXL Cache Text Encoder Outputs: true
- SDXL No Half VAE: true
- Seed: 42
- Shuffle Caption: false
- Single Dim: (empty)
- Single Module Dim: (empty)
- Split Mode: false
- Split QKV: false
- Stop Text Encoder Training: 0
- T5XXL:
/mnt/shared-assets-lg/CLIP/t5xxl_fp16.safetensors - T5XXL LR: 0
- T5XXL Max Token Length: 512
- Text Encoder LR: 0
- Timestep Sampling: sigmoid
- Train Batch Size: 1
- Train Blocks: all
- Training Data Directory:
/mnt/private/train/flux/img/ - Train Norm: false
- Train on Input: true
- Train T5XXL: false
- Training Comment: (empty)
- Text Attention Dimension: (empty)
- Text MLP Dimension: (empty)
- Text Module Dimension: (empty)
- UNET Learning Rate: 0.0003
- Unit: 1
- Up LR Weight: (empty)
- Use CP: false
- Use Scalar: false
- Use Tucker: false
- V2: false
- V Parameterization: false
- V Pred Like Loss: 0
- VAE: (empty)
- VAE Batch Size: 0
- WandB API Key: (empty)
- WandB Run Name: (empty)
- Weighted Captions: false
- Xformers: sdpa
