

Exploring Stable Diffusion Extensions
Hey there! Welcome to RunDiffusion.
We're all about blending Ai with creativity to make something truly special. This document? It's your friendly guide to the coolest stuff happening in the world of Stable Diffusion extensions – the tech that's changing the game for artists and designers like you.
We're on a pretty awesome journey into this new world of AI-powered creativity, and we want you to join us. It's not just about making things better; it's about transforming the way we create. These Stable Diffusion extensions we're talking about? They're not just upgrades – they're game-changers.
So, what's in store below? We're going to take a stroll through the different Stable Diffusion extensions that we've been playing around with at RunDiffusion. Each one is its own little revolution, pushing what we thought was possible with AI.
Let's dive in and explore these cool tools!
Adetailer
- Detail Enhancement: The primary function of Adetailer is to add finer details to the images generated by the model. This can include sharper edges, more intricate textures, or more nuanced color gradations.
- Post-processing Step: Adetailer is usually applied as a post-processing step after the initial image generation. Once Stable Diffusion creates an image based on the input text, Adetailer processes this image to refine its details.
- Improving Realism: The goal of using Adetailer is to enhance the realism or artistic quality of the generated images. It helps in overcoming some limitations of the base model in capturing intricate details.
- Customization: Users can often customize how Adetailer works, controlling the extent of detail enhancement based on their specific needs or the requirements of a particular project.
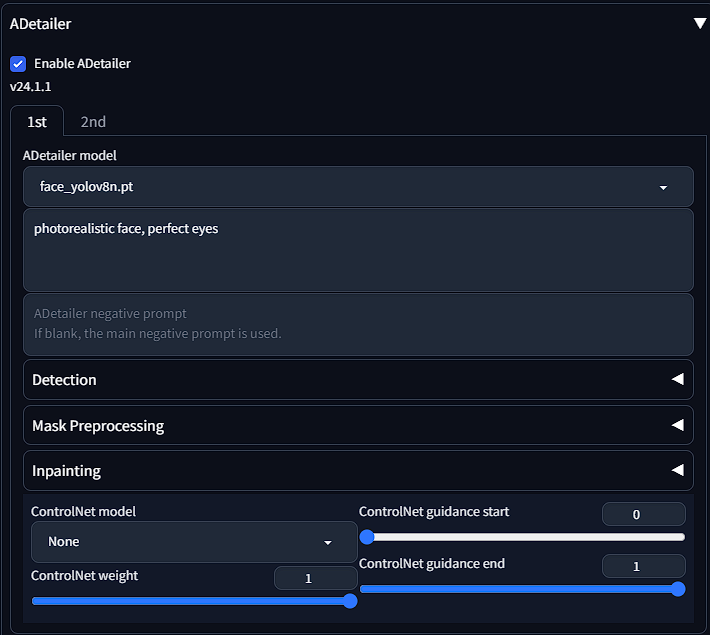
The first dropdown is to select the model of what you are trying to fix. See chart below.
| face_yolov8n.pt | 2D / realistic face | 0.660 | 0.366 |
| face_yolov8s.pt | 2D / realistic face | 0.713 | 0.404 |
| hand_yolov8n.pt | 2D / realistic hand | 0.767 | 0.505 |
| person_yolov8n-seg.pt | 2D / realistic person | 0.782 (bbox) 0.761 (mask) | 0.555 (bbox) 0.460 (mask) |
| person_yolov8s-seg.pt | 2D / realistic person | 0.824 (bbox) 0.809 (mask) | 0.605 (bbox) 0.508 (mask) |
| mediapipe_face_full | realistic face | - | - |
| mediapipe_face_short | realistic face | - | - |
| mediapipe_face_mesh | realistic face | - | - |
The prompt box is where you input what exactly you are going after with Adetailer. Note that if you leave the prompt box empty, it will use the prompt you have for the overall generation. You can use LoRA in these prompts as well.
There are also other options including detection, mask preprocessing, and inpainting. Common settings you may want to tune are face detection in the detection tab and denoising in the inpainting tab. You can also use a Controlnet to guide the inpainting.
See Github for further information.
 Bing-su
Bing-suAgent-scheduler
Input your usual Prompts & Settings. Enqueue to send your current prompts, settings, controlnets to AgentScheduler.
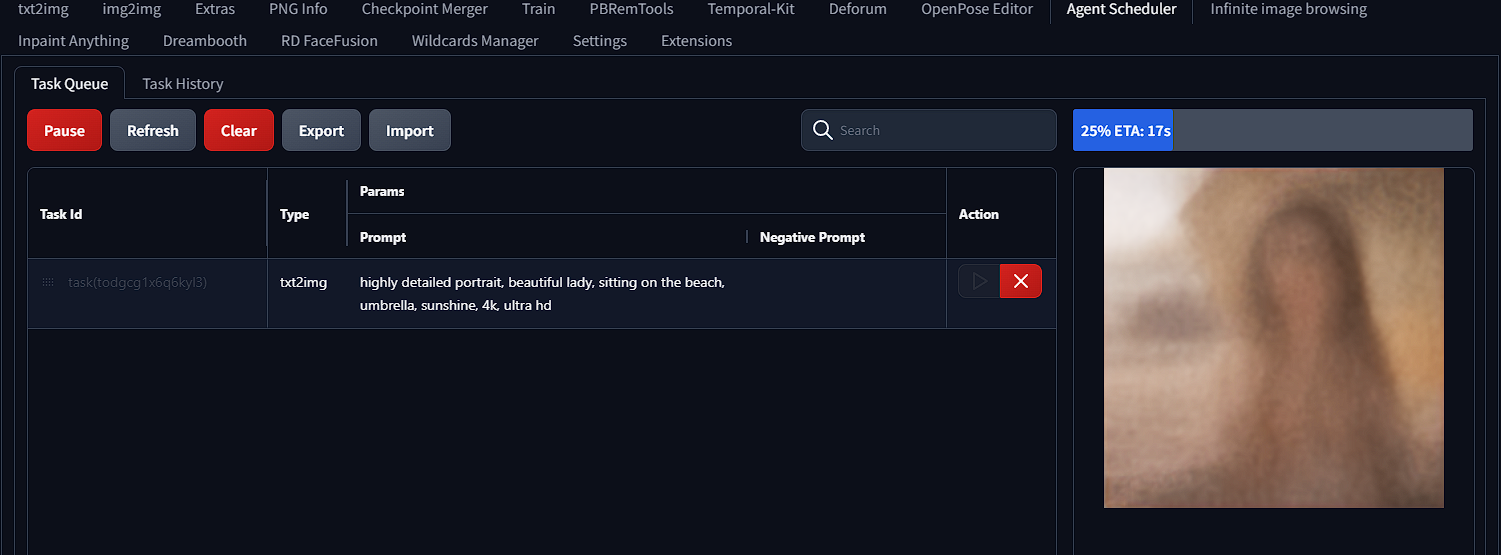
AgentScheduler Extension Tab.
See all queued tasks, current image being generated and tasks' associated information. Drag and drop the handle in the begining of each row to reaggrange the generation order.
Pause to stop queue auto generation. Resume to start.
Press ▶️ to prioritize selected task, or to start a single task when queue is paused. Delete tasks that you no longer want.
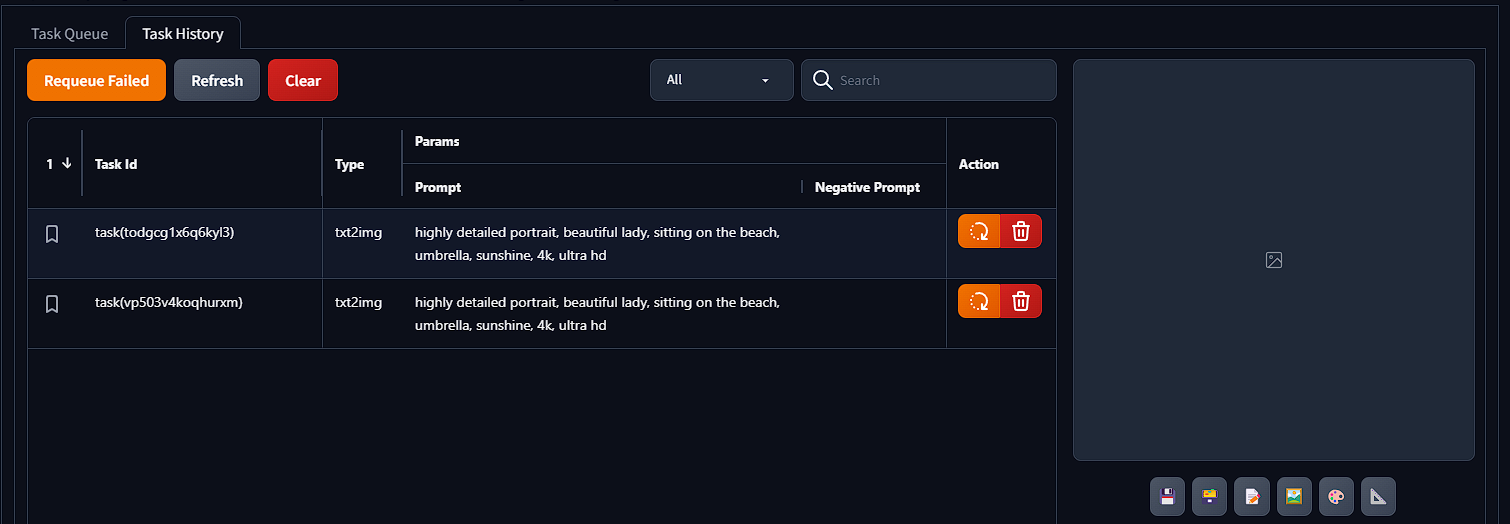
Task History
Filter task status or search by text.
Bookmark task to easier filtering.
Double click the task id to rename and quickly update basic parameters. Click ↩️ to Requeue old task.
Click on each task to view the generation results.
See Github for further information.
ArtVentureXAnimatediff
Animation of Still Images: The primary purpose of AnimateDiff is to animate still images generated by Stable Diffusion. It adds motion to previously static images, creating a short animation or video clip.
Sequence Generation: AnimateDiff works by generating a sequence of images that represent frames of an animation. Each frame is slightly altered from the previous one to create the illusion of motion when played in sequence.
To create an AnimateDiff
Enter prompt>select model>select number of frames>select fps>select loop number>select MP4>Generate
See Github for further information.
continue-revolution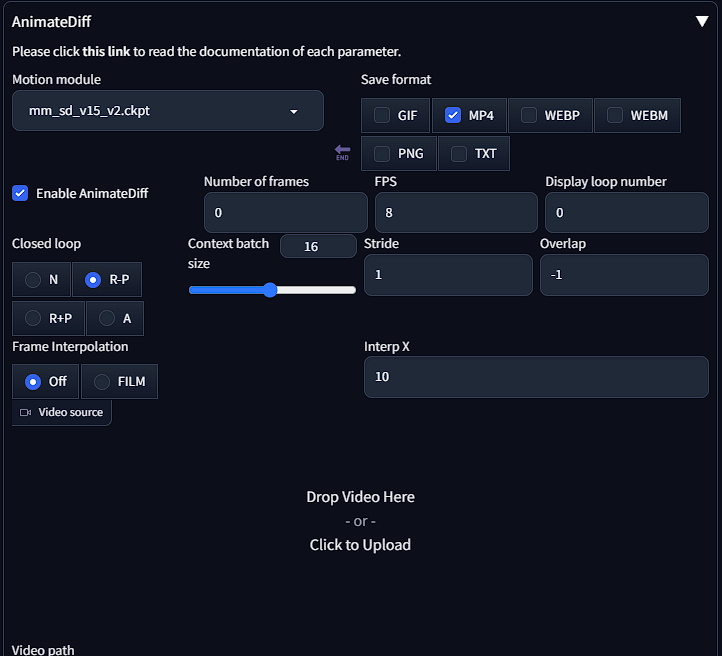
Canvas-zoom
Adds the ability to zoom into Inpaint, Sketch, and Inpaint Sketch.
Here is a list of keyboard commands:
Shift + wheel - Zoom canvas
Ctr + wheel - Change brush size
Ctr-Z - Undo last action
F (hold) - Move canvas
S - Fullscreen mode, zoom in on the canvas so that it fits into the screen.
R - Reset Zoom.
Q - Open/Close color panel
T - Open color panel right above the mouse.
H - Fill the entire canvas with brush color ( Works in Sketch and Inpaint Sketch )
A - Toggle dropper ( Works in Sketch and Inpaint Sketch )
O - Overlap all elements and back
C - Toggle mask transparency mode ( Works only in Inpaint )
[ - Increase brush size
] - Decrease brush size
Additional hotkeys
Shift + wheel (hold) - Move canvas
Shift + "+" or Shift + "-" - Scale canvas ( numpad keys also work )
![Screenshot showing Inpaint ) [ - Increase brush size ] - Decrease brush size Additional hotkeys Shift + wheel (hold) -...](https://storage.ghost.io/c/79/65/7965787d-54cb-4211-8169-3d231a1bb6f8/content/images/2024/01/image-62.png)
See Github for further information.
richrobber2Controlnet
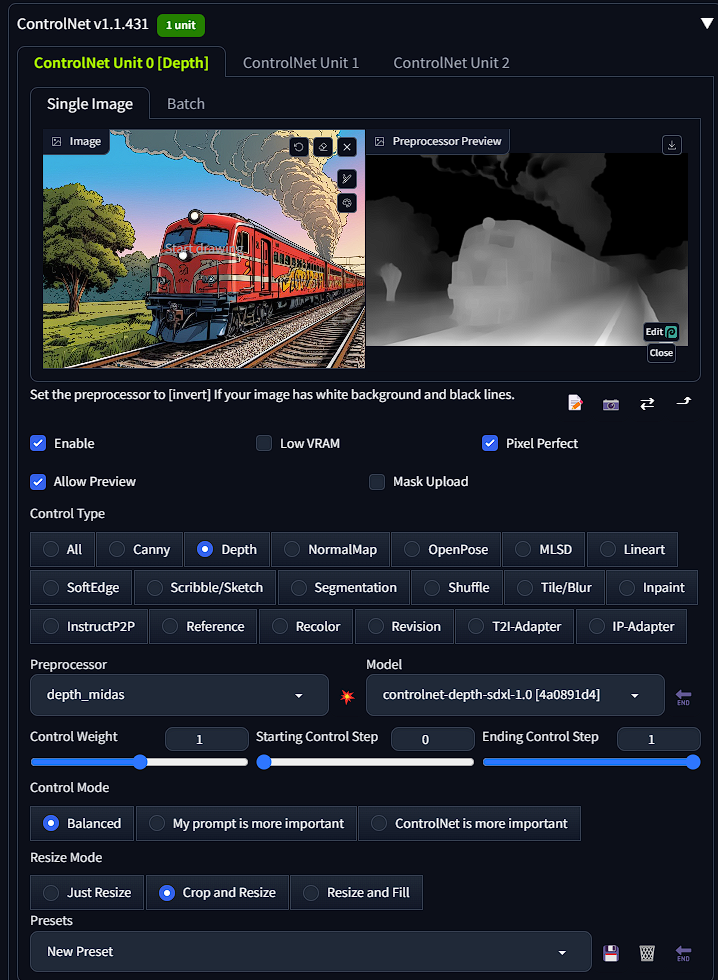
ControlNet for Stable Diffusion is a component of a machine learning model designed to enhance the control and precision of image generation tasks. In the context of Stable Diffusion, which is a deep learning model for generating detailed images from textual descriptions, ControlNet acts as a guiding mechanism.
It works by allowing more precise control over specific aspects of the generated image, such as the layout, composition, or inclusion of particular elements. This enhanced control is particularly useful in tasks where the fine details and specific attributes of the generated image are crucial. ControlNet effectively helps in steering the diffusion process (the core of Stable Diffusion) towards desired outcomes, based on the inputs and constraints provided.
 PixelPirate
PixelPirate
See Github for further information.
MikubillDeforum
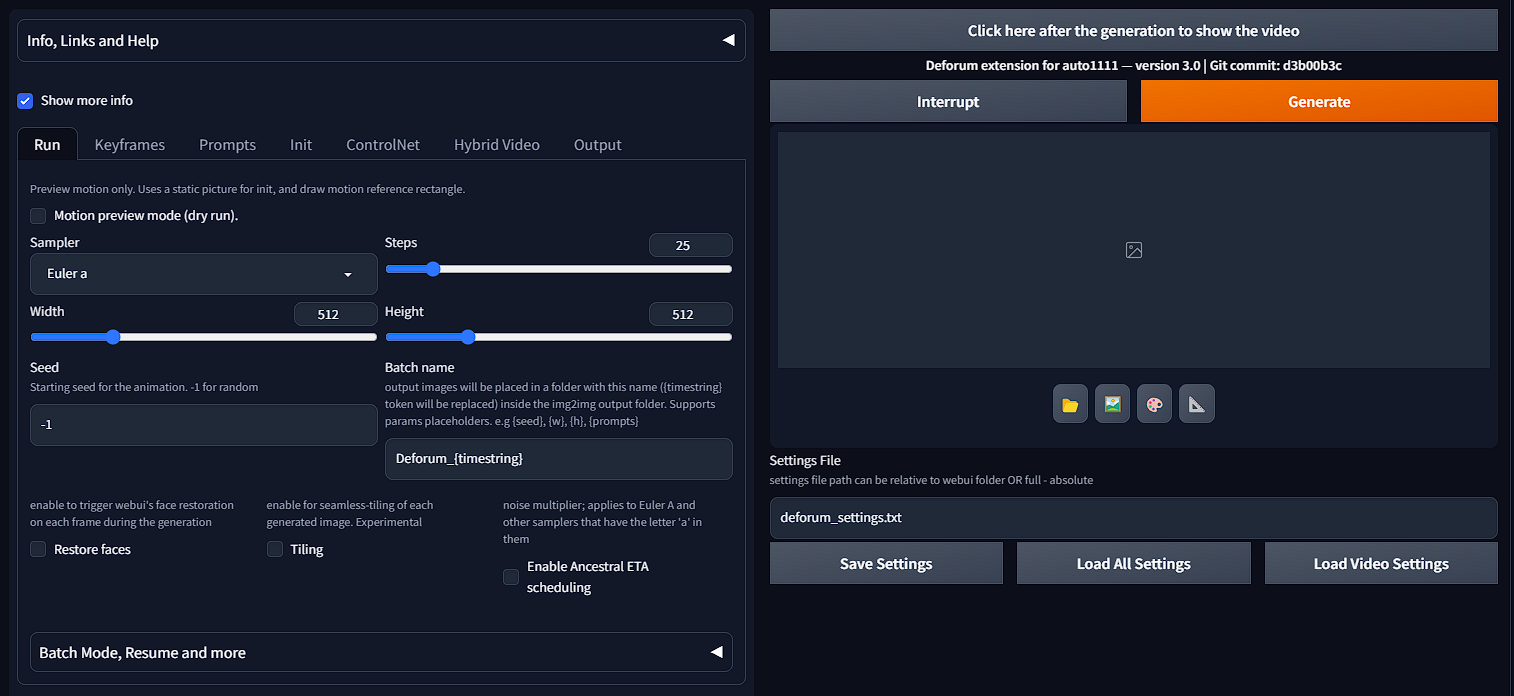
Deforum is an extension of Stable Diffusion WebUI, solely made for AI animations. It's a powerful tool that lets you create 2D, 3D, Interpolation, or even add some art style to your videos.
 Ed
Ed
See Github for further information.
deforum-artDreambooth
"DreamBooth" is a research concept and technique in the field of artificial intelligence, specifically within the domain of generative models like Stable Diffusion. The primary goal of DreamBooth is to personalize generative models to create custom content based on a small set of example images.
Here's a brief overview of how DreamBooth works:
- Personalization with Few Examples: DreamBooth allows a generative model to learn from a small set of images (as few as three to five) about a specific subject. This subject could be a particular person, animal, object, or scene.
- Retraining the Model: The process involves retraining a part of the generative model using these images. This retraining doesn't change the model's overall capability to generate a wide range of images but adds a new 'skill' to generate images of the specific subject learned from the provided examples.
- Generating Customized Content: After retraining, the model can create new images that include the learned subject in various contexts and settings. For instance, if you train the model with images of a specific dog, it can then generate new images of that dog in scenarios or poses it was never in before.
- Preserving Original Capabilities: Importantly, this personalization is done while preserving the model's original capabilities. It doesn't forget how to generate other types of images; it simply adds the new subject to its repertoire.
- Applications: The applications of DreamBooth are diverse and include personalized content creation, branding, art generation, and more. It can be particularly useful for creating consistent visual themes involving specific subjects that are not widely represented in the training data of the original model.
DreamBooth represents a significant step in the customization and personalization of AI-generated content, allowing users to create unique and tailored images with minimal input.
EdSee Github for further information.
d8ahazardDynamic-prompts
Dynamic prompts implements an expressive template language for random or combinatorial prompt generation along with features to support deep wildcard directory structures.
You can outline the different aspects of the prompt you want to change by using the " | " Break key and enclosing the descriptors in " { } ". Ensure you also change the batch size to increase the number of images you want to generate, normally driven by how many different concepts you have in your prompt. Below is an example.
A {house|apartment|lodge|cottage} in {summer|winter|autumn|spring}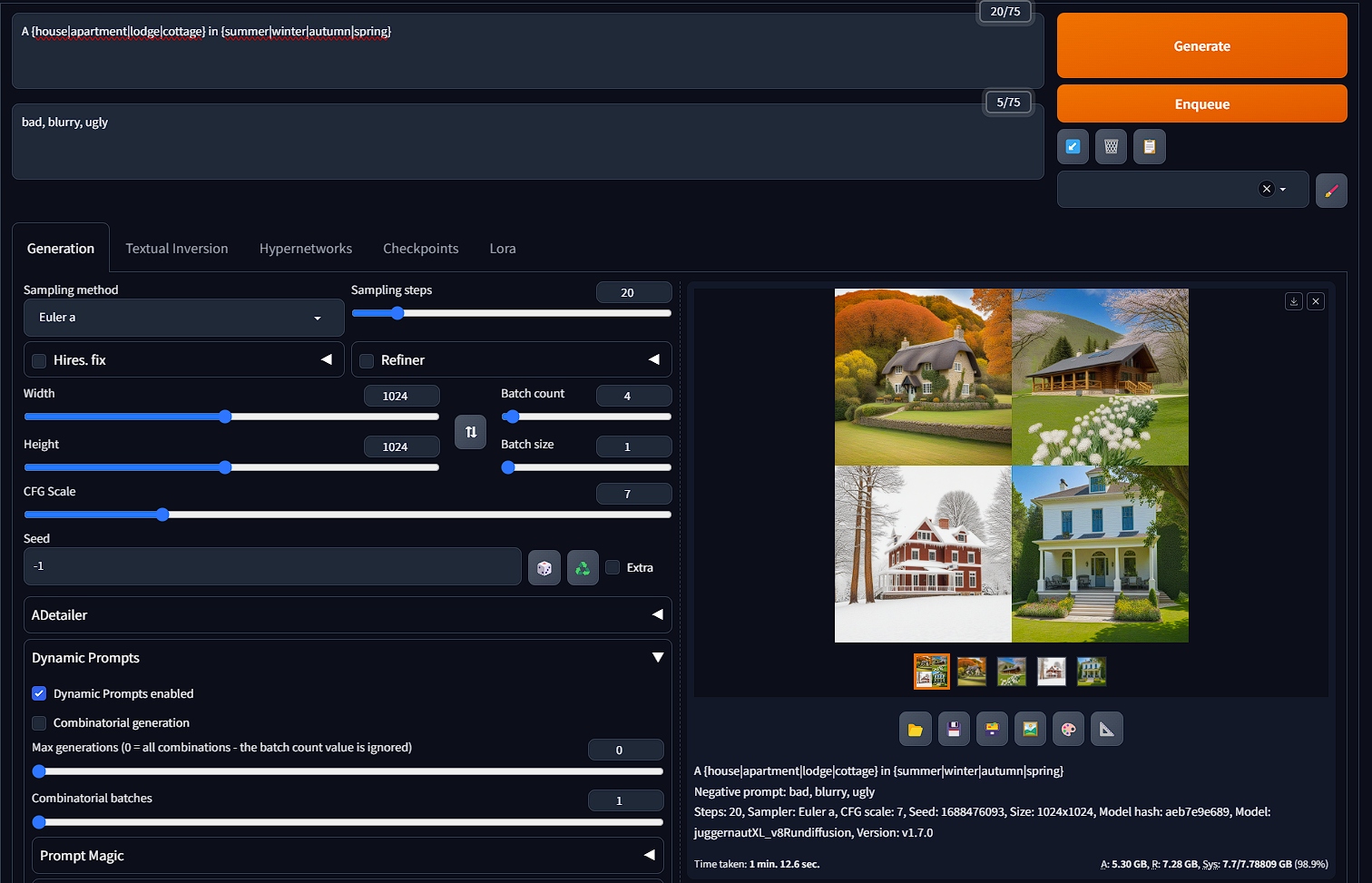
See Github for further information.
adieyalInfinite-image-browsing
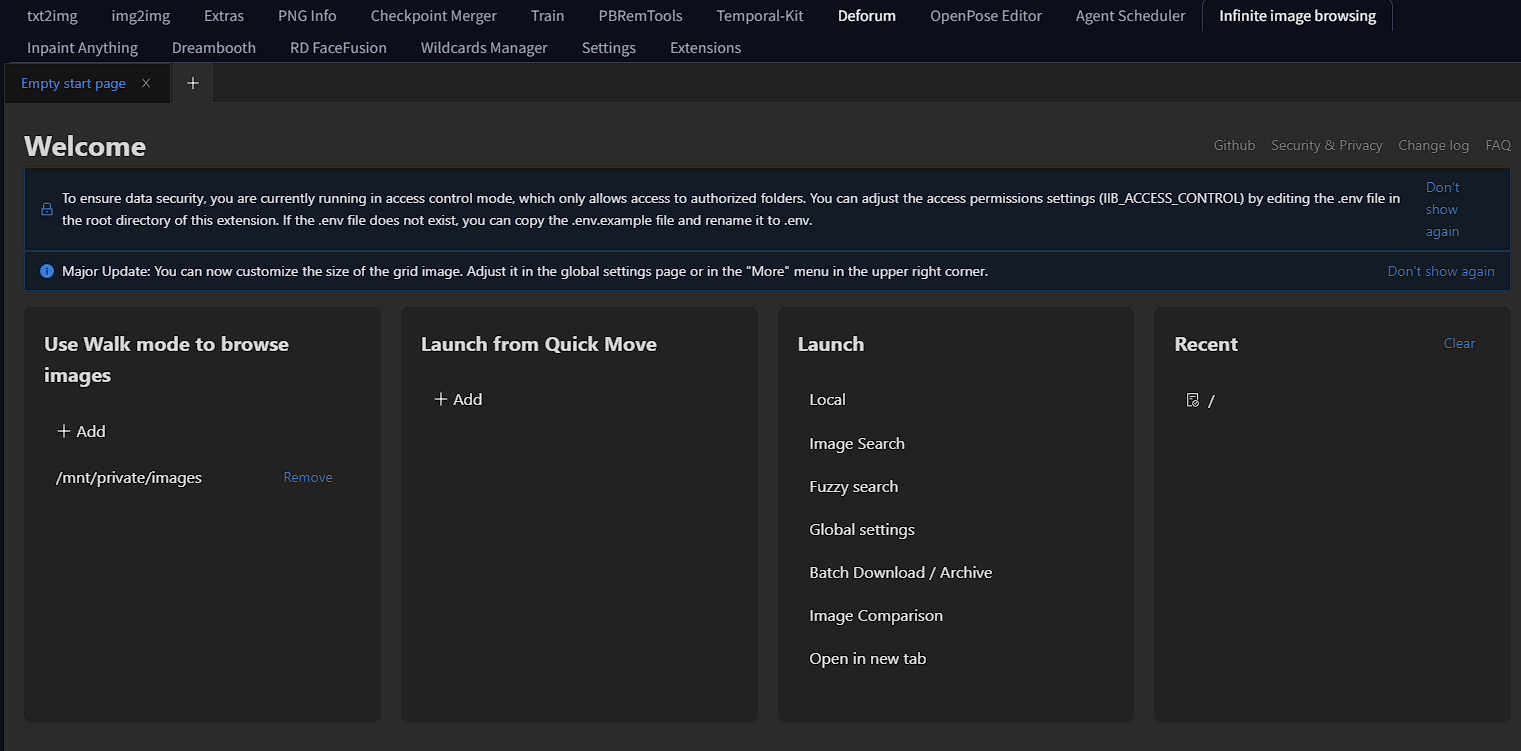
To start, you will find all your images under the "local" button underneath the "launch" menu on the third box from the left. This will house your whole local drive of /mnt/private/images. You can also open multiple windows in the top left to have a window for each app (Auto1111, fooocus, comfy, etc).
You also can click the three dots on the upper right of each photo for tools like generation data, sent to, and more.
Key Features
🔥 Excellent Performance
- Once caching is generated, images can be displayed in just a few milliseconds.
- Images are displayed with thumbnails by default, with a default size of 512 pixels. You can adjust the thumbnail resolution on the global settings page.
- You can also control the width of the grid images, allowing them to be displayed in widths ranging from 64px to 1024px.
🔍 Image Search & Favorite
- The prompt, model, Lora, and other information will be converted into tags and sorted by frequency of use for precise searching.
- Supports tag autocomplete, auto-translation, and customization.
- Image favorite can be achieved by toggling custom tags for images in the right-click menu.
- Support for advanced search similar to Google
- Also supports fuzzy search, you can search by a part of the filename or generated information.
- Support adding custom search paths for easy management of folders created by the user.
See Github for further information.
zanllpInpaint-anything
Inpaint Anything extension performs stable diffusion inpainting on a browser UI using any mask selected from the output of Segment Anything.
Using Segment Anything enables users to specify masks by simply pointing to the desired areas, instead of manually filling them in. This can increase the efficiency and accuracy of the mask creation process, leading to potentially higher-quality inpainting results while saving time and effort.
See Github for further information.
UminosachiOpenpose-editor
Open pose is used for generating a pose you want your character to have while generating in txt2img/img2img. Head to the open pose tab and create your pose.
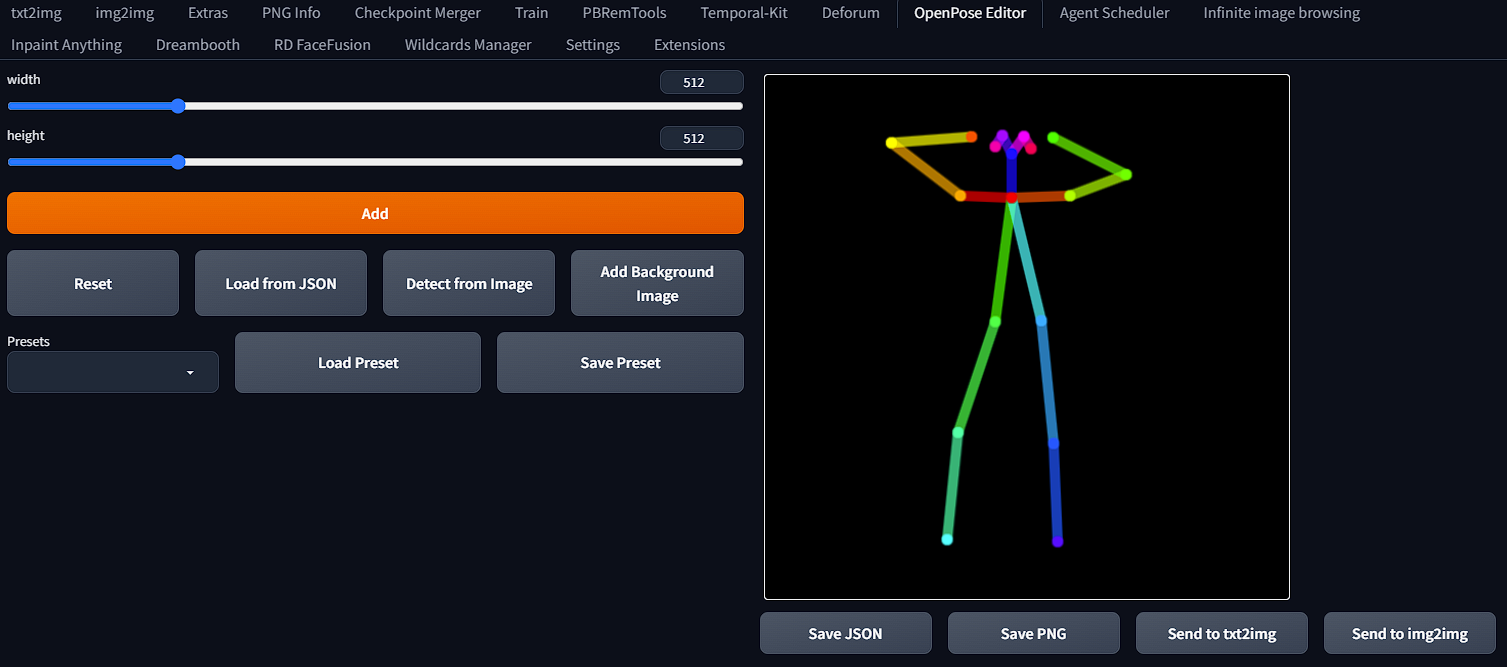
You can then select "send to txt2img". Once in txt2img you will notice the pose under controlnet. Ensure you have "enabled" selected as well as "open pose" for the preprocessor and model.
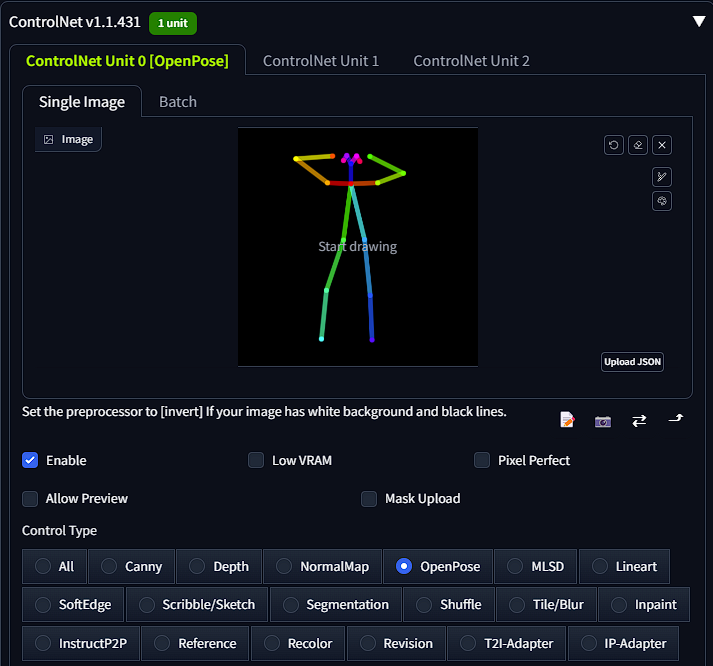
Once complete you can head up to the prompt box where you will input your prompt and begin the process. Ensure to add details about your open pose to help the generation.
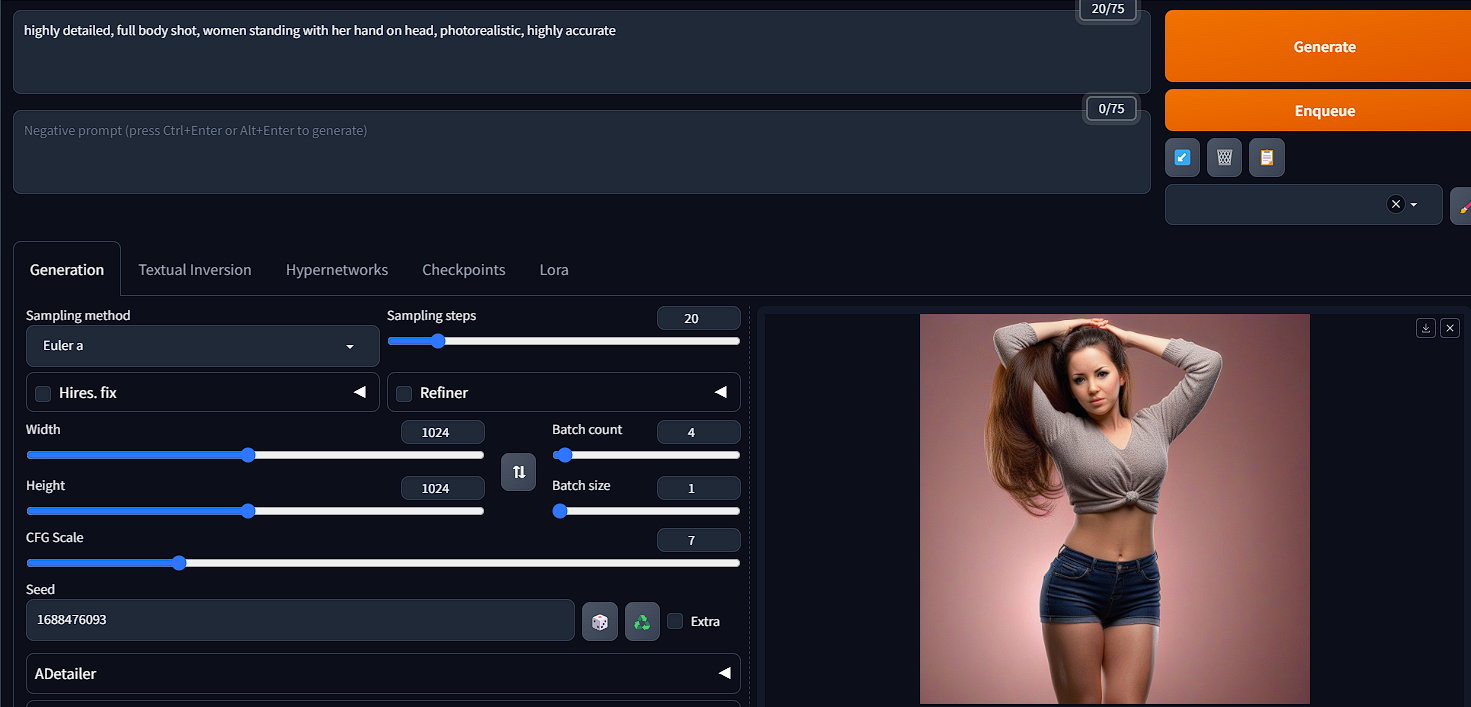
See Github for further information.
fkunn1326PBRemTools
PBRemTools(Precise background remover tools) is a collection of tools to crop backgrounds from a single picture with high accuracy. This is a very easy tool to use, simply upload a picture, enable the model and then scroll down and select "submit". After a short while, POOF. Magical.
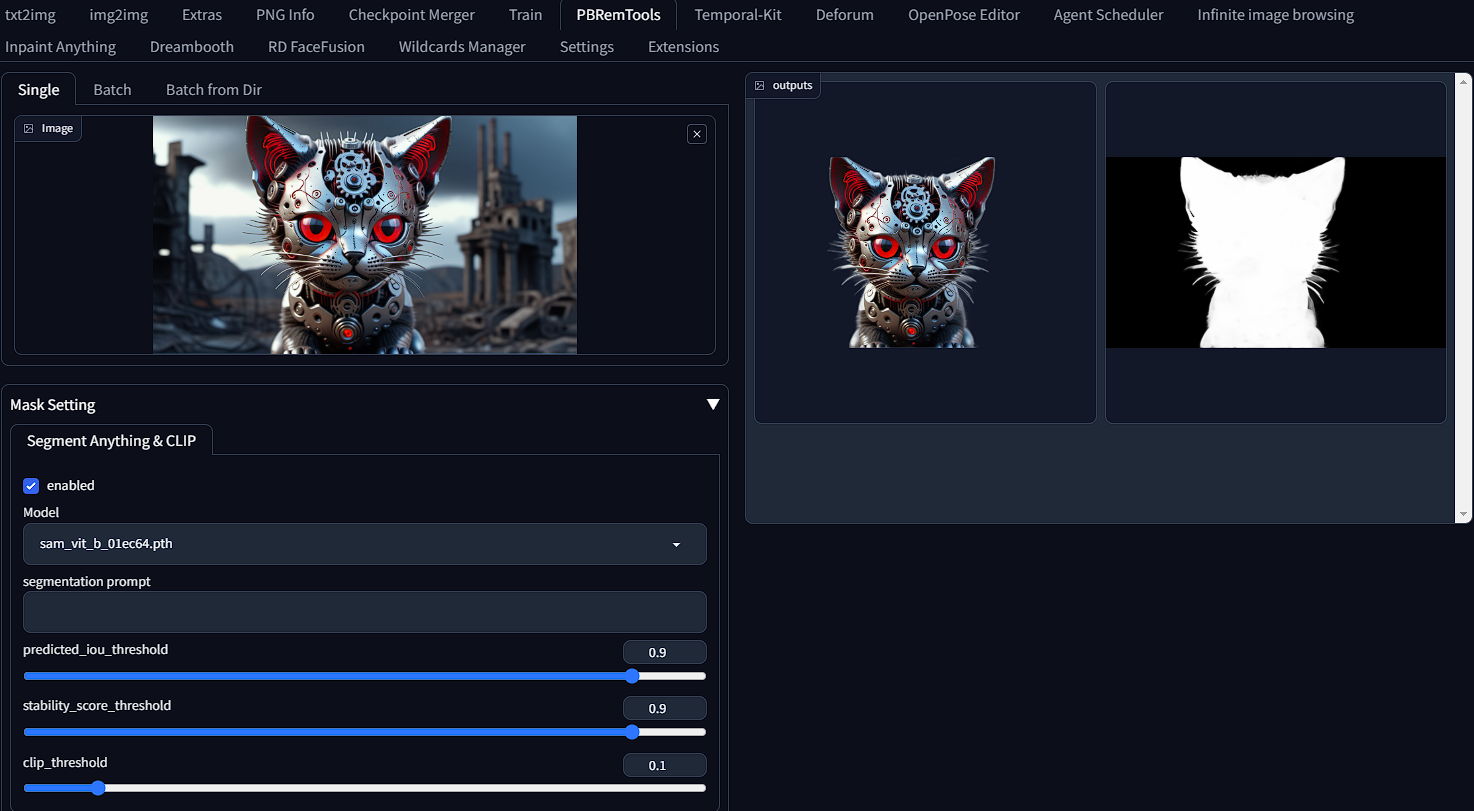
See Github for further information.
d8ahazardReactor
Reactor is a fast and simple face swap extension.
See Github for an in-depth overview of how to use Reactor.
GourieffRegional-prompter
Regional prompter is a very in-depth extension that allows control over your image like no other.
See Github for a full review of how it works and the many different options you have available to you.
hako-mikanTemporalKit
An all in one solution for adding Temporal Stability to a Stable Diffusion Render via an automatic1111 extension
See Github for full overview of TemporalKit
CiaraStrawberryWe hope you enjoy all we have to offer. We will be continuously updating and reviewing new extensions as they become available and chosen ones will be added to our collection and updated on this workflow.
RunDiffusion