


FramePack, a next-frame video diffusion framework from lllyasviel, is now available to run directly through RunDiffusion's cloud platform.
This integration gives users access to FramePack’s unique context-packing approach for efficient video generation—without needing to set up the project locally.
What is FramePack?
FramePack introduces a method for next-frame prediction in video diffusion models. It compresses the context of previously generated frames into a fixed-length representation, allowing the model to focus only on relevant prior information. This results in a consistent input size for each generation step, regardless of how many frames have been generated.
This framework is designed for progressive video generation, where frames are created one-by-one in sequence. The goal is to improve performance and reduce compute requirements during both training and sampling.
The official repository is here:
Core Features (from the repository)
- Progressive Frame-by-Frame Video Generation
- Context Compression: Packs earlier frames into a condensed form before predicting the next frame.
- Sampling System Included: Comes with a simple high-quality sampling pipeline for evaluation and demo purposes.
- Training Code Provided: Training scripts for learning frame prediction using standard datasets.
The authors note that it helps keep the input size constant and allows the model to operate without performance degradation as the number of frames increases.
How to Use FramePack on RunDiffusion
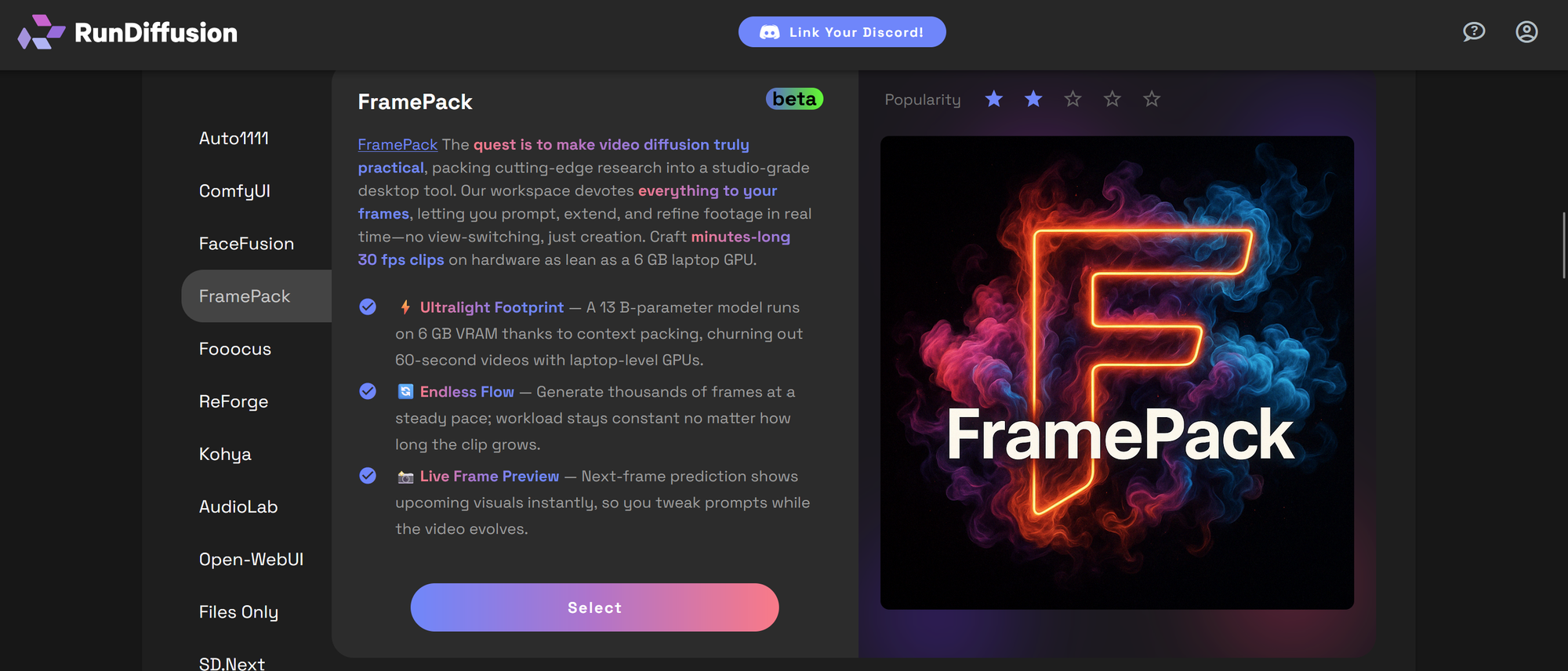
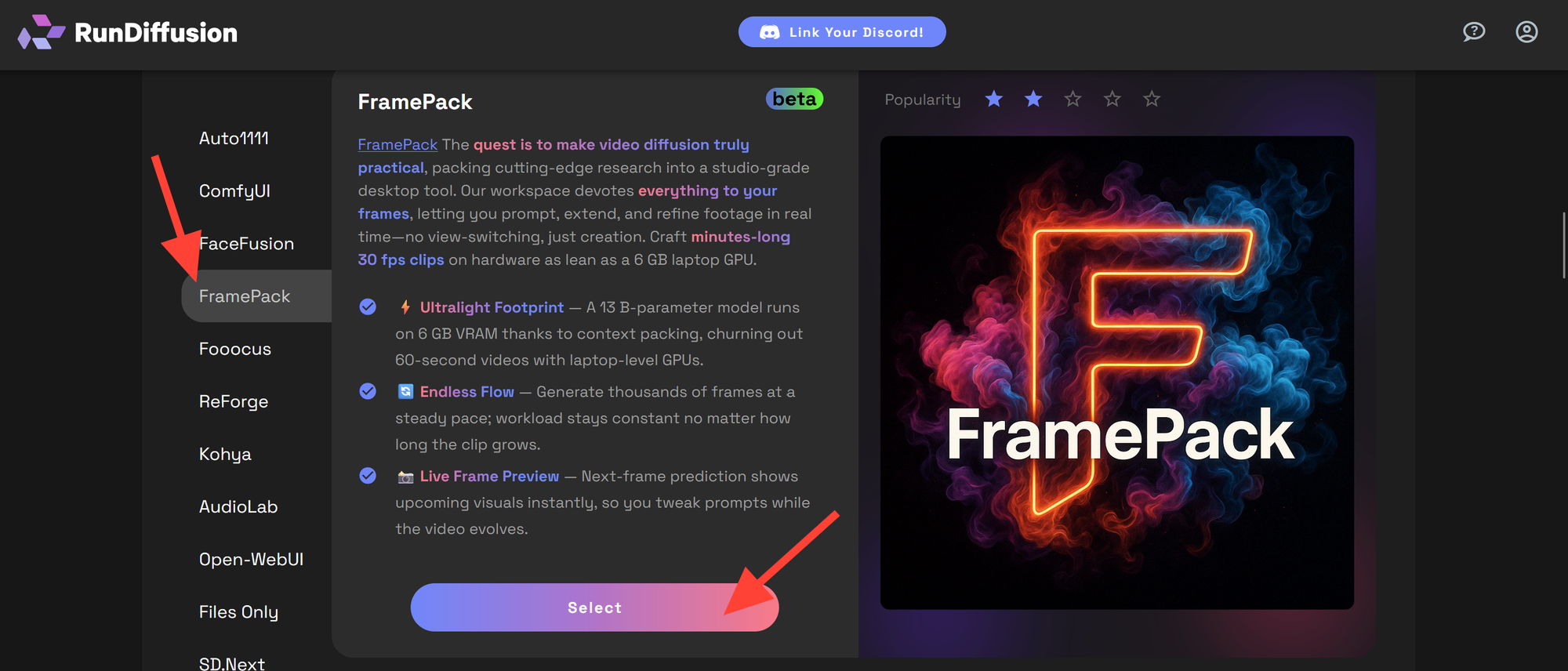
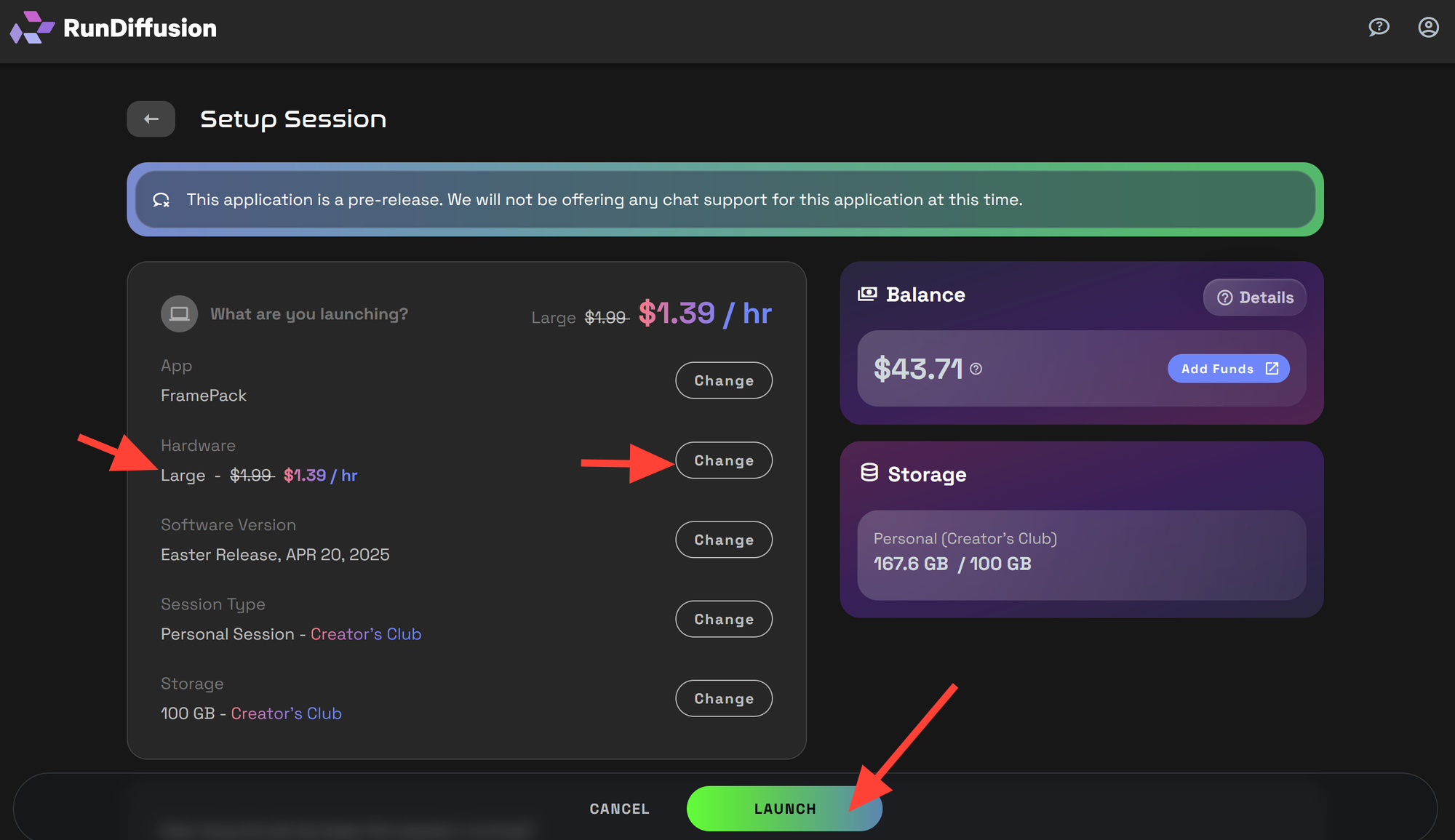
Click on FramePack in the left-hand menu and then click Select.
Set your session parameters, then click Launch to start your session. We recommend at Large server for video work.
Drop or Upload an Image.
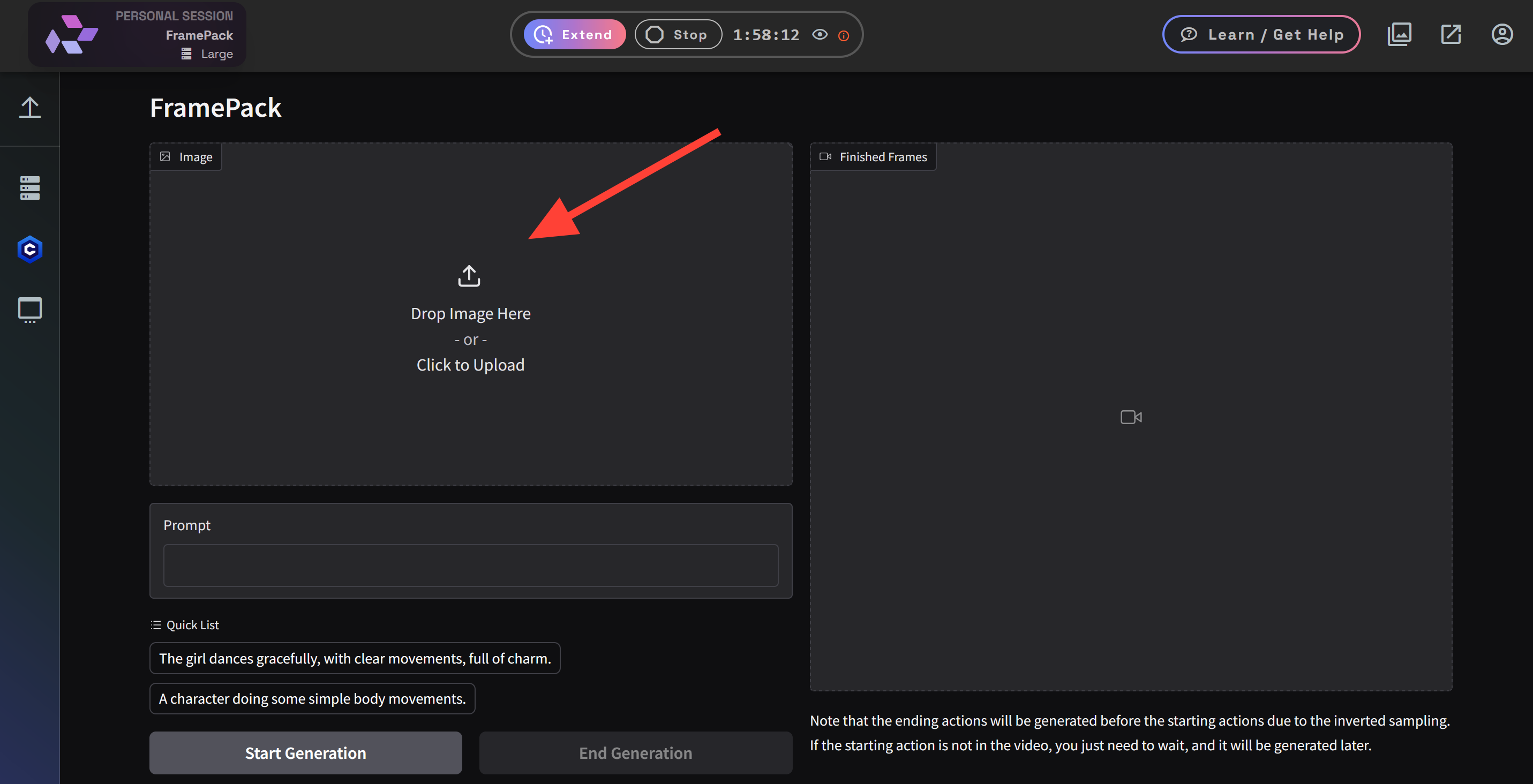
Enter a Prompt.
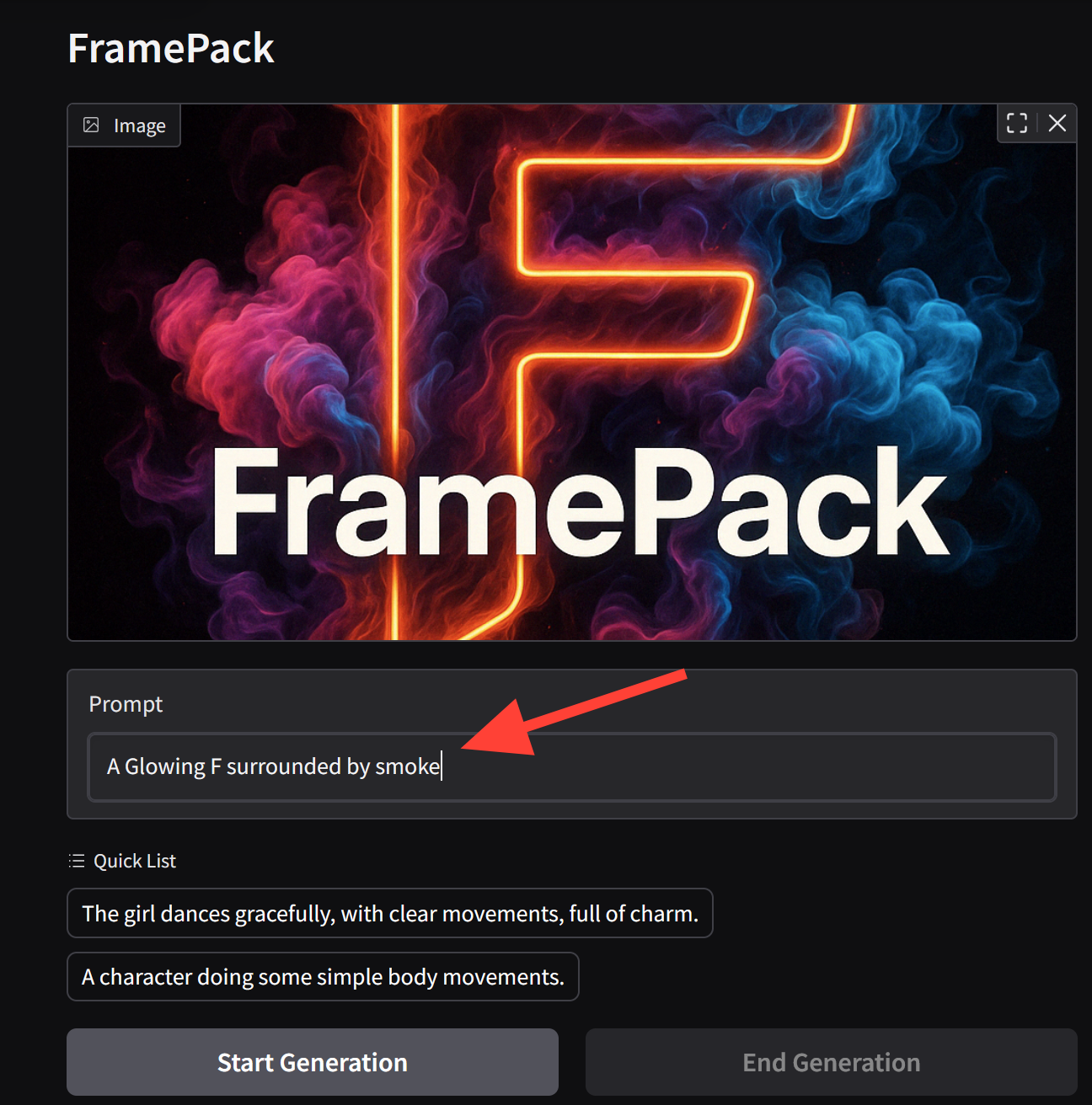
Check your settings. You can change your Total Video Length. This may drastically change processing time. A 5 second video takes about 10-11 minutes.

When your settings are what you'd like click Start Generation.
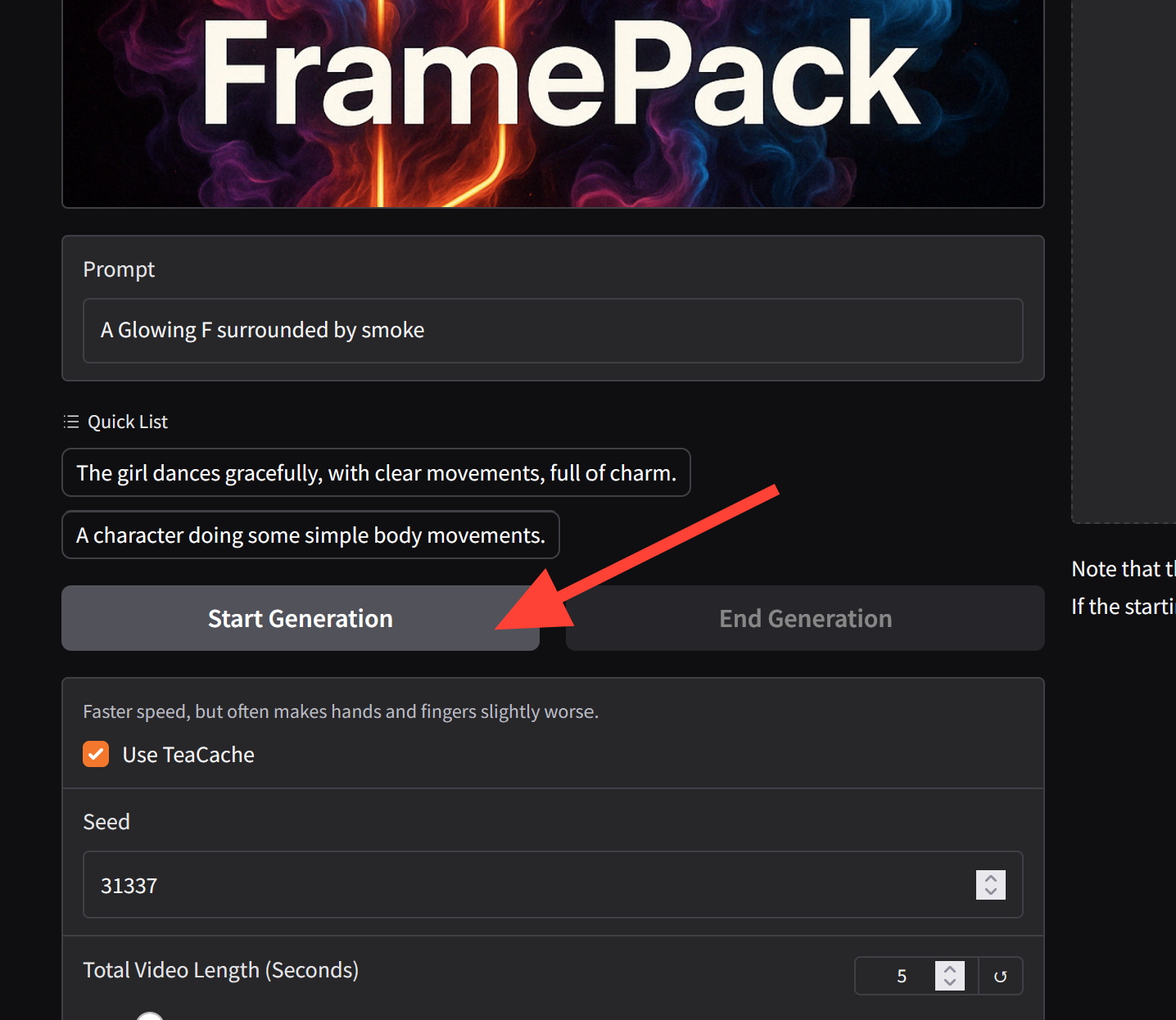
While the video is processing. You can End the Generation early if needed.

After processing you can download your video by clicking on the download symbol.

Example Videos.
5 Second Video
40 Second Video:
Related Reading
If you’re working with video and animation in diffusion models, you may also find these RunDiffusion guides useful:



